











AIガイドラインに学ぶAI開発でデータは著作権により保護されるか

はじめに
AI開発で「学習済みモデル」を創りだすには、大量の「データ」が必要になります。
もっとも、最終的な成果物である学習済みモデルを創りだすためのプログラム部分の多くはOSSとして公開されていますので、プログラムだけでは差がつかないのが実情です。そのため、いかにして良質なデータを大量に集められるか、という点がビジネスの勝負の源泉ともなります。
このように、「データ」は学習済みモデルの生成に不可欠であるため、AI開発はベンダとユーザーとの共同開発的な色彩が強いといえます。
そうであるからこそ、このようなデータについて、誰にどのような権利が認められるか、という点はユーザーにとっては極めて重要な関心事といえます。
そこで今回は、AI開発には欠かすことのできない「データ」について、誰にどのような権利が認められるのか?特に、コンテンツを保護する権利である「著作権」で保護されるのかという問題を中心に、ITに強い弁護士が解説していきます。
1 AIの成果物の種類

「AI(人工知能)」は、「Artificial(人工的な)」と「Intelligence(知能)」の頭文字を組み合わせた略称で、見る、聞く、話す、考えるなどの人間的な活動をコンピュータに行わせる仕組みをいいます。
AIには、人間と同様に経験を積むことで学習して成長する「汎用型AI(強いAI)」と、人間がこれまでにやってきたことを代替的に行うだけの「特化型AI(弱いAI)」とがあります。
もっとも、現状では、「汎用型AI(強いAI)」を開発するまでには至っておらず、一般的にいうAIは「特化型AI(弱いAI)」のことを指しています。
以下は、AI開発のフローを図にしたものです。
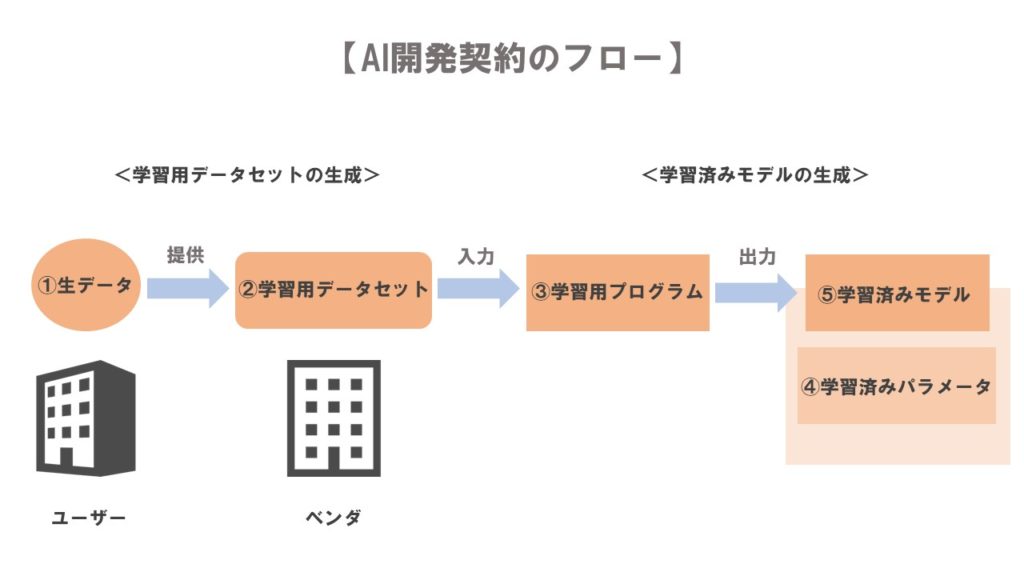
このように、AIはその開発過程で以下の5つの成果物を生み出すことになります。
- 生データ
- 学習用データセット(加工データ)
- 学習用プログラム
- 学習済みパラメータ
- 学習済みモデル
(1)生データ
「生データ」とは、AIが学習しやすいように変換処理や加工処理をしたデータのことをいいます。AIが学習しやすい「形式」にしたものが生データであり、「内容」までは加工していないデータのことをいいます。
たとえば、インターネット上の画像や文章などのデータが「生データ」にあたります。
(2)学習用データセット(加工データ)
「学習用データセット(加工データ)」とは、AIに学習させやすくするために、生データの中から学習済みモデルの生成に適していないデータを除いたデータのことをいいます。
学習済みモデルの生成に適していないデータとしては、たとえば、他のデータとかけはなれた値を示すデータなどが考えられます。このような不適切なデータを取り除いたり、別のデータを加えたりして、AIに学習させやすくするためのデータを生成するわけです。
(3)学習用プログラム
「学習用プログラム」とは、学習用データセットによって学習し、学習済みモデルを生成するために必要なプログラム部分のことをいいます。
(4)学習済みパラメータ
「学習済みパラメータ」とは、学習用データセットによる学習結果として得られたパラメータ(係数)のことをいいます。
直接は、多くのデータを基礎としてAIが自動的に生成することになります。
(5)学習済みモデル
「学習済みモデル」とは、学習済みパラメータが組み込まれた学習用プログラムをいうとされており、学習用プログラムと学習済みパラメータの2つで成り立っているとされています(※定義には争いがあります)。
以上のように、AIの開発過程ではいくつもの成果物が生み出されます。
そのため、それぞれについて誰にどのような権利が認められるのか、といった点が問題となるのです。
今回は、この中でも特に「①生データ」と「②学習用データセット(加工データ)」にフォーカスして、それぞれについて誰にどのような権利(著作権)が認められるのか、を見ていきたいと思います。
2 AIの「データ」は著作権で守られるのか?

ビジネスに役立つような高精度の学習済みモデルを生成するには、AIに学習をさせるために大量のデータを読み込ませることが必要になります。生データを大量に集めることや、その生データを加工して学習用データセット(加工データ)にすることには、多くの手間とお金がかかります。
また、学習用データセットのクレンジング(前処理)やデータオーギュメンテンション(拡張技術)などに貴重なノウハウがあったり、顧客データなどといったようにデータ自体に価値があるものもあります。
そのため、データの作成者は、いかにしてそのデータを保護するかという問題に直面することになります。
(1)生データ
「生データ」には、小説、論文、絵画、楽曲、気温などさまざまな種類があります。これらのデータが「著作物」にあたれば著作権法で保護されますが、あたらなければ著作権法では保護されません。
ここでいう「著作物」といえるためには、次の4つの条件をみたす必要があります。
- 思想または感情であること
- 表現されていること
- 創作性(オリジナリティ)があること
- 文芸、学術、美術、音楽の範囲に属していること
小説や論文、絵画などはいずれも思想・感情が創作性(オリジナリティ)をもって表現されているため、これらの条件をすべてみたしています。
そのため、生データが小説や論文、絵画などのように創作性があるものであれば、著作権法で保護されます。
他方で、気温などは単なる事実にすぎないため、著作権法では保護されません。
もっとも、生データが単なる事実にすぎず、それ自体は著作物にあたらない場合であっても、集積された生データがコンピュータによって検索可能になるように体系的に構成されているケースがあります。
このような場合、生データの情報選択や体系的な構成に創作性(オリジナリティ)が認められれば、「データベースの著作物」として、著作権法により保護されます。
「データベースの著作物」の詳細については、後ほど解説します。
このように、「生データ」は先に挙げた4つの要件をすべてみたしていれば、「著作物」として著作権法で保護されます。
また、生データ自体が著作物にあたらない場合であっても、「データベースの著作物」にあたるのであれば、同様に著作権法で保護されることになります。
(2)加工データ(学習用データセット)
AIの精度を向上させたり、AIに効率性の高い学習をさせるためには、生データの中から良質なデータを選んだり(クレンジング)、データ量を増やすためにノイズを入れる(オギュメンテーション)などといった加工が必要になってきます。
これらの加工作業には、大きな労力・費用を割かなければなりません。
また、生データの提供者やAI開発者は、それぞれにデータの取扱いや加工についてのノウハウをもっており、これらのノウハウがあるかないかで、AIの精度にも影響してきます。
そのため、生データを加工などする際には、多くの場合、このノウハウを用いることになります。
そこで、このようにノウハウを駆使されるなどして加工されたデータをいかにして保護するか、という点も問題になります。
この点は、以下のように2つに分けて考えることができます。
①「データベースの著作物」として保護されないか?
データが単なる事実に過ぎず、それ自体は著作物にあたらなくても、「データベースの著作物」にあたれば、著作権法で保護されます。
「データベースの著作物」として保護されるためには、まずは、加工データが著作権法上の「データベース」にあたることが必要です。
「データベース」にあたるためには、
-
(ⅰ)論文、数値、図形その他の集合物であること
(ⅱ)(ⅰ)に係る情報をコンピュータを使って検索できるように体系的に構成していること
という2つの条件をみたしている必要があります。
以上の2つの条件をみたし、さらに、以下の2つの条件をみたしている場合に初めて「データベースの著作物」にあたることになります。
-
(ⅰ)集めたデータがコンピュータにより検索可能な状態になっていること
(ⅱ)データの情報選択または体系的な構成について創作性があること
加工データの生成過程では、AIの学習に適合する良質なデータの選択を重ね、独自に生データを加工していくことになるため、創作性のある「情報選択または体系的な構成」を生み、「データベースの著作物」にあたる可能性が高くなるということがいえます。
このように、加工データは独自に生データを加工していくことで生成されるデータであるため、加工データが「データベース」にあたり、さらに、以上に挙げた2つの条件をみたせば、「データベースの著作物」として著作権法で保護されることになります。
それでは、加工データが「データベースの著作物」にあたらず、著作権法で保護されない場合、一切の保護を受けられないということになるのでしょうか。
このような場合には、民法上の「不法行為」を根拠として、保護される可能性があります。
②民法上の「不法行為」で保護されないか?
「不法行為」とは、違法に他人の権利・利益を侵害することをいいます。
たとえば、人がわざと・うっかり他人が所有する車に傷を付けてしまったような場合に不法行為が成立します。
不法行為が成立するためには、
-
(ⅰ)人の権利・利益を侵害すること
(ⅱ)故意・過失があること
(ⅲ)損害が発生したこと
という3つの条件をみたす必要があります。
「故意」とは、わざとその行為をすることをいい、「過失」とは、不注意(うっかり)によりその行為をしてしまうことをいいます。
このことを「加工データ」にあてはめて見てみると、以下のような場合に不法行為が成立する可能性が出てくるということになります。
(著作権法では保護されない)加工データについて、法律上保護される他の利益を観念することができ、その利益をわざと・うっかり無断でコピーされ、損害が発生したような場合です。
この点、著作権法では保護されないデータベースの無断コピーについて、「不法行為」の成立を認めた裁判例があります。
他方で、著作権法で保護されない作品について、「特段の事情がないかぎり不法行為は成立しない」と判断した裁判例もあります。「特段の事情」とは、先で述べた「法律上保護される他の利益」が侵害されているなどの事情があることを指します。
たとえば、同じ業界で競合関係にあるA社とB社があると想定しましょう。A社が多大な時間と労力を割いて生成したデータベースをB社が無断でコピーしたとします。
A社が生成したデータベースがA社の営業活動に使われており、大変価値があると認められる場合に、このデータベースには「営業活動上の利益」があると認められることがあります。
このような場合には、B社がA社の「営業活動上の利益」を侵害したとして、B社に不法行為が成立する可能性があります。
裁判例からいえることは、著作権法では保護されないデータベースの無断コピーなどについて、不法行為が成立するかどうかは著作権法が保護する利益とは違う「法律上保護される利益」を観念できるかどうかによって結論が分かれるということです。
そのため、加工データを無断でコピーするなどといった行為については、そのデータに「法律上保護される利益」が認められれば、「不法行為」が成立する可能性が高いといえます。
このように、生データや加工データ(学習用データセット)については、「著作物」や「データベースの著作物」として著作権法で保護される可能性をもっています。
そこで次に問題となるのが、生データや加工データの提供者が、それらを元に生成される「学習済みパラメータ」について、どのような権利を持つのか、ということです。
3 データ提供者は「学習済みパラメータ」に対しどのような権利を持つのか?

「学習済みパラメータ」とは、学習用データセットを使ってAIに学習させることで得られる係数のことをいいます。生データを加工したものが学習用データセット(加工データ)であり、学習用データセットを使うことで得られるものが学習済みパラメータです。
そのため、生データや学習用データセットを提供した「データ提供者」が、学習済みパラメータに対しても何らかの権利を持てるのでは?と考えることは何ら不思議ではありません。
そこで、データ提供者が学習済みパラメータに対しどのような権利を持つのかということが問題になります。
この点については、以下の3つの可能性が考えられます。
(1)「二次的著作物」の可能性
「二次的著作物」とは、すでに存在する著作物を翻案することにより創作した著作物のことをいいます。「翻案」とは、「すでに存在する著作物」について、表現上の本質的な特徴に変更を加えることなく、具体的な表現などに修正を加えるなどして、「新たに思想などを創作的に表現すること」をいいます。仮に、二次的著作物にあたる場合、元となった著作物に係る著作権者の権利が二次的著作物にも及ぶとされています。
生データや学習用データセットが著作物にあたると前提した場合、生データや学習用データセットが「すでに存在する著作物」、学習済みパラメータが「新たに創作した著作物」ということになります。
そのため、学習済みパラメータが「二次的著作物」にあたる場合、データ提供者の著作権が学習済みパラメータにも及ぶことになります。
この点、学習済みパラメータは先にも述べたとおり、学習用データセットを使ってAIに学習させることで得られる「係数」にすぎないため、生データや学習用データセットに認められる「表現上の本質的な特徴」が学習済みパラメータにおいても維持されているとは言えません。
そのため、学習済みパラメータが「二次的著作物」にあたるとされる可能性はほとんどありません。
(2)「共同著作物」の可能性
「共同著作物」とは、2人以上が共同して創作した著作物をいい、それぞれが著作者としてその創作に関わっていることが必要です。
仮に、学習済みパラメータが「共同著作物」にあたる場合、データ提供者は学習済みパラメータについて、著作権(共有)を有することになります。「二次的著作物」とは異なり、生データや学習用データセットが著作物にあたるかどうかは関係ありません。
この点、インターネット上にアップされているデータを利用して学習済みパラメータを生成した場合、データ提供者は学習済みパラメータのもとになるデータを単に提供しただけにすぎず、学習済みパラメータの生成に関わっているわけではありません。
そのため、データ提供者が学習済みパラメータの共同著作者となることはありません。
もっとも、データ提供者がその提供を通じてAIの精度をあげるために必要な作業をするなど、学習済みパラメータの生成に深く関わっているような場合には、データ提供者が共同著作者となる可能性があります。
以上のように、「学習済みパラメータ」が二次的著作物にあたる可能性は極めて低いですが、「共同著作物」にあたる可能性はあります。学習済みパラメータが共同著作物にあたる場合、データ提供者は学習済みパラメータについて、著作権(共有)を持つことができます。
(3)「目的外利用」の可能性
データ提供者は、AI開発者にデータを提供する前に、AI開発者との間で「秘密保持契約」を結ぶことが一般的です。秘密保持契約書では、秘密情報をその契約の目的の範囲内でしか使用できないとする旨の条項を定めることが通常です。
学習済みパラメータを契約の目的の範囲内でしか使用できないとする旨の条項を含む秘密保持契約書をAI開発者との間で結ぶことで、データ提供者はAI開発者に対し、学習済みパラメータを目的の範囲内でしか使用させないという契約上の権利を持つことができます。
そのため、学習済みパラメータの利用が目的外利用にあたる場合、データ提供者はそのことを理由に契約違反を主張できることになります。
もっとも、「目的外利用」といえるかどうかは、契約上の「目的」をどのように解釈するかによって異なります。
また、データ提供者とAI開発者との間に解釈上の食い違いがあり、紛争に発展する可能性も秘めています。
そのため、秘密保持契約を結ぶ際には、学習済みパラメータの取扱いについて疑義が生じないよう、しっかりと話し合い、そのルールを明確に定めておくことが大切です。
以上のように、「データ」や「学習済みパラメータ」といったAI開発の過程で生み出される成果物には、著作権を始めとした一定の権利が認められる場合がありますが、ここで少し視点を変え、AI開発のためにデータを「利用」することにどういった問題があるのかについて見ていきたいと思います。
※なお、秘密保持契約書の「目的外利用」の禁止に関する条項の書き方やレビューについて詳しく知りたい方は、「【ひな形付】秘密保持契約書(NDA)の書き方と20個のポイント」をご覧ください。
4 AIデータの「利用」に伴う法律問題(情報解析)

現代の情報社会では、データをインターネットから集めたり、第三者に提供することは日常的に行われています。
もっとも、著作権法の観点からは、このような行為は「著作権侵害」にあたる可能性があります。このことは、AI開発においても同様にあてはまります。
AI開発では、ユーザーが、AIに学習させるためのデータをインターネットなどから収集し、ベンダに提供します。ですが、このデータの中には誰かが著作権を有するデータが含まれているかもしれません。そのようなデータを提供されたベンダは、そのデータを「利用」して、AIに学習させることになります。
この点、ベンダが自社で作成したデータを利用することは、問題なく可能です。
問題となるのは、利用するデータが他社が作成したデータであって、そのデータにつき他社が著作権を持っている場合です。
この場合、データの利用について他社の許可を得ている場合には著作権を侵害することにはなりません。
もっとも、ユーザーから提供されるデータは膨大であることがほとんどであるため、このような場合にいちいち許可を得ることは現実的ではありません。
そこで、改正著作権法は、それまでに禁止されていた一部のことを例外的にできるようにしました。
(1)何ができるのか?
著作物の利用方法の一つとして「情報解析」を目的とした利用がありますが、この場合には、著作権者の許可を受けることなく著作物を利用することができます。
「情報解析」とは、大量の情報の中から言語や音声などの情報を抜き出し、比較や分類を行うことをいいます。
AIに学習させるためにデータを利用することは、「情報解析」にあたるとされているため、「情報解析」を目的とした利用であれば、著作権者の許可なくデータを利用できることになります。
この場合、データの「利用方法」は限定されていないため、「翻案」や「コピー」の他、共同開発者の間でデータを共有するなどの「公衆送信」なども自由にできます。
また、データの「利用目的」も限定されていないため、学習済みモデルを売る目的でデータを利用する場合であっても著作権者の許可は必要ありません。
このように、「情報解析」を目的として著作物を利用する場合には、利用方法・利用目的を問わず原則として自由に著作物を利用することができます。
(2)何ができないのか?
「情報解析」を目的として著作物を利用する場合でも、データの利用が無制限に認められるわけではありません。
以下の2つにあてはまる態様での著作物の利用は禁止されています。
- 必要な範囲を超えている
- 著作権者に不利益が生じる
たとえば、情報解析をする人のために作成された「データベースの著作物」を著作権者の許可なく利用することは、「著作権者に不利益が生じる利用」にあたると考えられています。情報解析をする人のために作成された「データベースの著作物」には、情報解析に利用する大量のデータがすでに入っていて、検索しやすくするために独自の工夫がこらされています。このデータベースを著作権者の許可なしに情報解析のために利用することができるとすると、著作権者にとって大変不利益です。
そのため、情報解析をする人のために作成された「データベースの著作物」を利用する場合には、著作権者の許可を受けなければなりません。
以上のように、著作物を利用する際には、原則として著作権者の許可を受ける必要がありますが、「情報解析」のために著作物を利用する場合には、その利用が必要な範囲にとどまっており、著作権者に不利益が生じないのであれば、著作権者の許可を受けることなく、著作物を自由に利用できることになります。
※なお、改正著作権法について詳しく知りたい方は、「2018年著作権法改正の概要とは?4つのポイントを弁護士が解説!」をご覧ください。
5 小括

AIに学習させるデータには大きな価値があるため、データがどのように保護されるのかという問題は、データを提供する事業者などにとっては大変強い関心事です。
この点を十分に理解しておくことにより、自社が主張できる権利だけでなく、反対に、他社の権利を侵害することになるのか、という点も適切に判断することが可能になります。
無用なトラブルを避けるためにも、権利の種類や所在などをしっかりと理解したうえで、適切にデータを取り扱うようにしましょう。
6 まとめ
これまでの解説をまとめると、以下のとおりです。
- AIのデータには、AIが学習しやすいように形式を加工した「生データ」と、生データの内容を加工した「学習用データセット」の2つがある
- 生データが「著作物」にあたる場合、または、著作物にあたらなくてもデータの集まりが「データベースの著作物」にあたる場合は、著作権法で保護される
- 加工データは「データベースの著作物」として保護される可能性がある
- 加工データが「データベースの著作物」として著作権で保護されない場合でも、不法行為による損害賠償を請求することができる
- データ提供者が学習済みパラメータにどのような権利をもつかという問題については、①二次的著作物の可能性、②共同著作物の可能性、③目的外利用の可能性を検討する必要がある
- AIに学習させるために他人のデータを利用することは「情報解析」にあたり、データ提供者の許可なしに利用することができる
- 情報解析にあたる場合でも、「必要な範囲を超える利用」と「著作権者に不利益が生じる利用」をするためには著作権者の許可が必要であり、「情報解析をする人のため」に作成された「データベースの著作物」を利用することは「著作権者に不利益が生じる利用」にあたる
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
現在は、企業法務を中心とした弁護士業務と、一橋大学大学院ソーシャル・データサイエンス研究科(M1)における研究の2軸で活動しています。 弁護士としては、IT・ゲーム・AI・FinTech分野を中心に、契約・利用規約、知的財産、個人情報保護、資金決済・金融規制、企業法務などを取り扱っています。 大学院では、法令工学を基盤として、法令データの構造化や生成AI・データサイエンスを活用した法情報処理に関する研究に取り組んでいます。







