












AI契約ガイドラインに学ぶAI開発契約6つの法律問題を弁護士解説

はじめに
AI開発についてベンダ・ユーザ間で契約をする際に、どのような点に注意し、どういった契約書を作成すべきなのかが分からず、お困りの事業者が多いのではないでしょうか?
特にAI開発によって生まれる学習済みモデル等の「成果物」について、どのような権利が認められ、それが自社に帰属するのか?といった点は非常に大事な問題ですよね。
この点について詳細に解説した「AI契約ガイドライン」という公的な文書もありますが、まるで古文・漢文の世界で、何を言っているのかさっぱりわかりません。
そこで今回は、主にAIを利用したソフトウェアの開発契約において注意すべきポイント、特に成果物の権利の所在等について、AI契約ガイドラインを紐解きながらわかりやすく弁護士が解説していきます。
1 AI開発契約とは

(1)AI開発契約
「AI開発契約」とは、AIベンダと、主にAIのソフトウェア等の開発を委託するクライアント企業(ユーザ)との間で結ばれる契約をいいいます。
AI開発契約は、通常、以下のようなプロセスで行われます。

このように、AI開発契約は、
- ユーザー:ベンダへ「生データ」を提供
- ベンダ:AIプログラム開発
- ベンダ:学習用データセットの生成
- ベンダ:学習済みパラメータを生成し、学習済みモデルを完成
↓
↓
↓
という過程を踏むことになります。
もっとも、AI開発契約は一般的な売買契約のように、売り手と買い手がそれぞれの義務を果たすことで契約関係が完結するという簡単な契約ではありません。後で詳細は説明いたしますが、AI開発契約はベンダ・ユーザ間の「共同開発」的な性質があり、それゆえに、AIの成果物の権利がどちらに帰属するのか?といった問題が生じます。
(2)AI開発契約の特殊性
AI開発契約は、既に見たとおり、ユーザーがベンダに対して、大元となる生データOR学習用データを提供することから始まります。このように、AI開発契約は「ユーザーの関与」を必ず必要とする契約であり、ユーザーが提供する生データの占める重要性もまた非常に高いということがいえます。そのため、ユーザーから提供された生データOR学習用データに基づいてなされるAI開発は「共同開発」的な性質を持つことになります。
もっとも、AI開発契約は、実際に物を作ってみないとどういった成果物ができあがるのか?がわからないという特殊性もあります。
そして、その特殊性から開発プロセスで生み出された「成果物」の
- 権利の帰属
- 責任の所在
という点を巡ってさまざまな問題が生じるわけです。
それでは、そもそも「成果物」についてはどのような権利が認められるのでしょうか。
次の項目から、詳しく見ていきましょう。
2 AI開発契約における「成果物」の権利

(1)「成果物」の種類
AI開発契約で問題となるのは、学習済みモデルをはじめとしたAI開発契約で生まれる様々な「成果物」について、誰に・どのような権利が認められるのか?という点です。
そのため、前提として、AI開発契約のプロセスで生まれる「成果物」の内容を簡単に確認しておきます。「成果物」は主に以下の4つに分けられます。
- 生データ
- 学習用データセット
- 学習済みモデル(学習用プログラム+学習済みパラメータ)
- ノウハウ
順番に見ていきましょう。
①生データ
「生データ」とは、AIのプログラム学習用に特に加工をしていない単なるデータのことをいいます。
②学習用データセット
「学習用データセット」とは、AIが学習しやすいように、生データを加工して作られた二次データのことをいいます。
③学習済みモデル
「学習済みモデル」とは、(定義に争いがあるものの)学習済みパラメータが組み込まれた学習用プログラムのことをいうとされています。
詳細は、追って解説しますが、「学習用プログラム」と「学習済みパラメータ」の二つから構成されるものが学習済みモデルとされています。
「学習用プログラム」とは、学習用データセットを通じて学習し、学習済みモデルを生み出すためのプログラムの部分を意味します。
「学習済みパラメータ」とは、学習用データセットを用いた学習の結果、得られたパラメータ(係数)のことをいいます。
④ノウハウ
「ノウハウ」とは、例えば、学習率、学習回数(エポック)やバッチサイズなどのハイパーパラメータをどのように設定するか?などの知見・ハウツーを意味します。
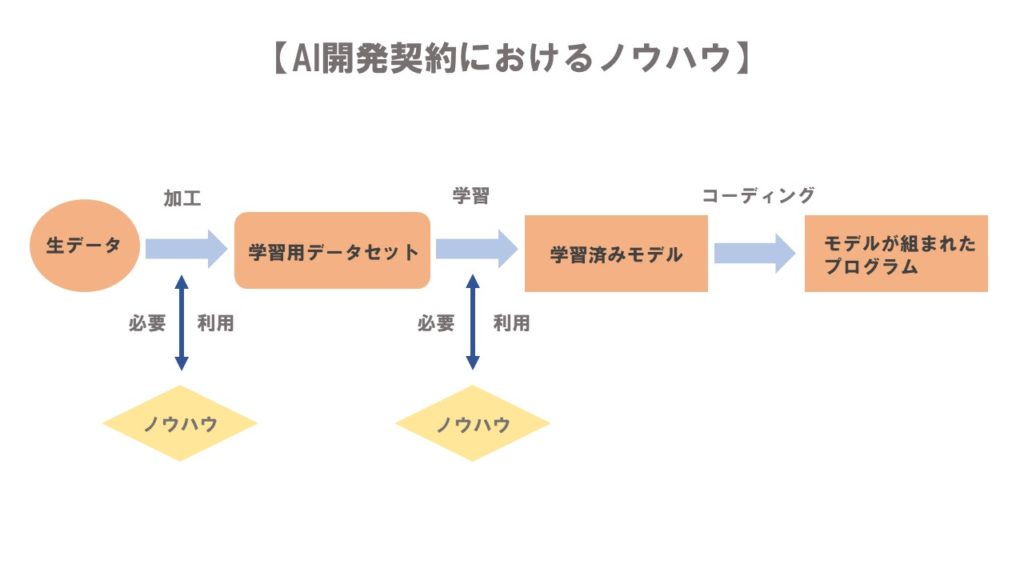
以上のように、AI開発から生み出される「成果物」は、主にはデータそのものであり、このようなデータそのものに法律上の権利が認められるかという点が①権利の帰属の問題の前提となるのです。
次に、AIの成果物に与えられる「権利」としては、どのようなものが考えられるでしょうか。以下で見ていきましょう。
(2)「権利」の種類
AIの成果物が法律で保護されるのかを考えるにあたっては、以下の3つの権利のいずれかで保護されないか?という観点から検討すると便宜です。
- 著作権
- 特許権
- 営業秘密等(不正競争防止法)
もっとも、AIが「特許」として保護される局面は、AIのプログラム自体がコモディティ化し、もっぱら有益な生データをどれだけ集められる?が勝負といわれるAI業界においては、限定的(というか戦略的な優位性に乏しい)です。
そのため、実際の思考方法としては、以下のフローで検討するのが有益です。
- 著作権法によって保護されるか?
- 保護されないとしても、不正競争防止法「営業秘密」などで保護されないか?
↓
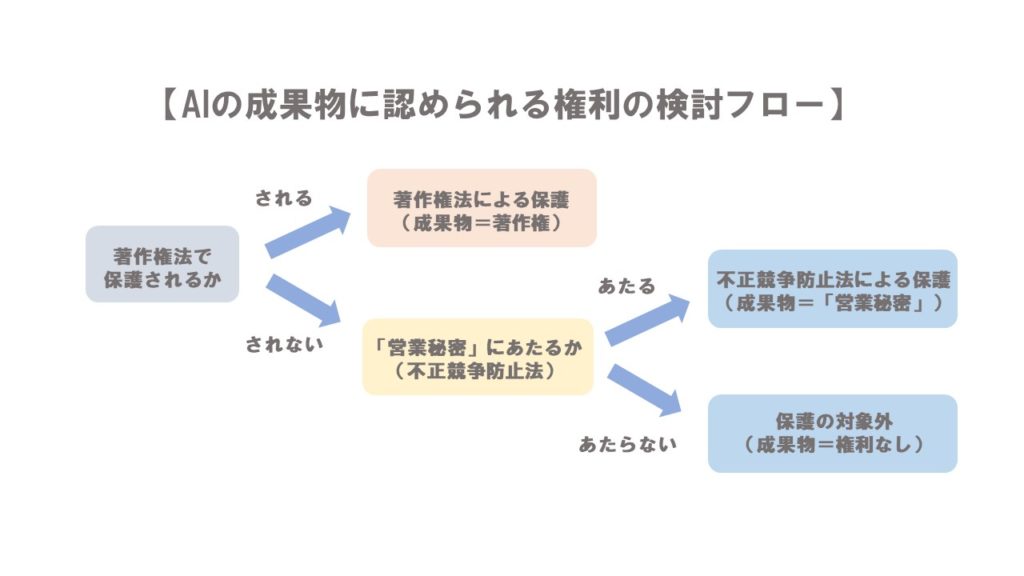
そして、仮に「成果物」にこれらのいずれかの権利が認められるにもかかわらず、勝手にビジネスに使ってしまうと、権利侵害として、損害賠償請求をされたり、場合によっては犯罪行為として刑事罰のペナルティを受ける可能性すらあります。
ここでは、以上3つの権利・法律について、その内容をさっと確認しておきます。
なお、実際のAI開発契約書でも誤解されている部分として、よく著作権のことを「所有権」と表現しているケースが散見されます。ですが、データ等は無体物(情報)であって、原則として有体物にのみ認められる「所有権」の対象とはなりませんので注意が必要です。
①著作権法とは?
「著作権法」とは、文芸や美術、音楽などに関して自分の思想や感情を創作的(オリジナリティ)に表現したもの(=著作物)やそれに隣接するさまざまな権利を保護するための法律です。著作物が他人に勝手に利用されないように、著作者に認められる著作権を守ってくれるわけです。
たとえば、原則として小説や音楽などの無断複製・転載が禁じられているのは、これらの著作物に「著作権」が認められているからです。
②特許法とは?
「特許法」とは、発明者に係る発明の保護などを目的とした法律です。他人に自己の発明を横取りされたり、無断で使われたりすることがないように、発明を保護することにより、発明を奨励し、ひいては産業の発達に寄与することを目的としています。
特許法上の「発明」といえるためには、「自然法則を利用した技術的思想の創作のうち高度のもの」と定義されていますので、すでに存在していたものであったり、個人の熟練などによって達成できるものは、「発明」にはあたりません。
③不正競争防止法とは
「不正競争防止法」とは、企業間における営業活動の正当性を守らせることにより、適正な競争を確保することを目的とした法律です。不正競争防止法は、たとえば、商品のデザインを丸パクリして販売している企業などのように、不正な行為に対して、その差止めや損害賠償請求をできることを認めている法律です。
このようにして、不正競争防止法は、不正な競争を排除しているのです。
これら3つの法律を理解しておくことは、AI開発契約に臨む当事者としては必須です。
その上で次に、AI開発契約において「誰が」成果物の権利を持つのかについての基本的なルールを確認します。
(3)「誰が」成果物の権利者か?の基本的な考え方
まず、基本的には、成果物を作った人が成果物の権利を持ちます。
著作権法であれば、コンテンツを生成した人が著作権を持ち、著作者となります。
特許法であれば、発明をした人が特許権を持ち、特許権者として保護されます。
これはAI開発契約にも当てはまります。
各種の成果物についても、契約などで「●●(ベンダorユーザー企業)が〇〇の成果物の権利を持つ」と明記しておかない限り、上記の原則に従って、成果物を作った人が権利者となります。
そのため、ベンダ・ユーザー企業ともにAI開発契約に臨む際には、以下の視点をもって自社に有利に交渉し、契約書に落とし込んでいく必要があります。
- 原則、成果物についてベンダ・ユーザーのいずれが権利を持つのか?を理解する
- その上で、相手方に権利がある成果物については、契約で明記して自分に移転できないか?
- ライセンスを受けて利用できないか(この点は後ほど解説します。)?
or
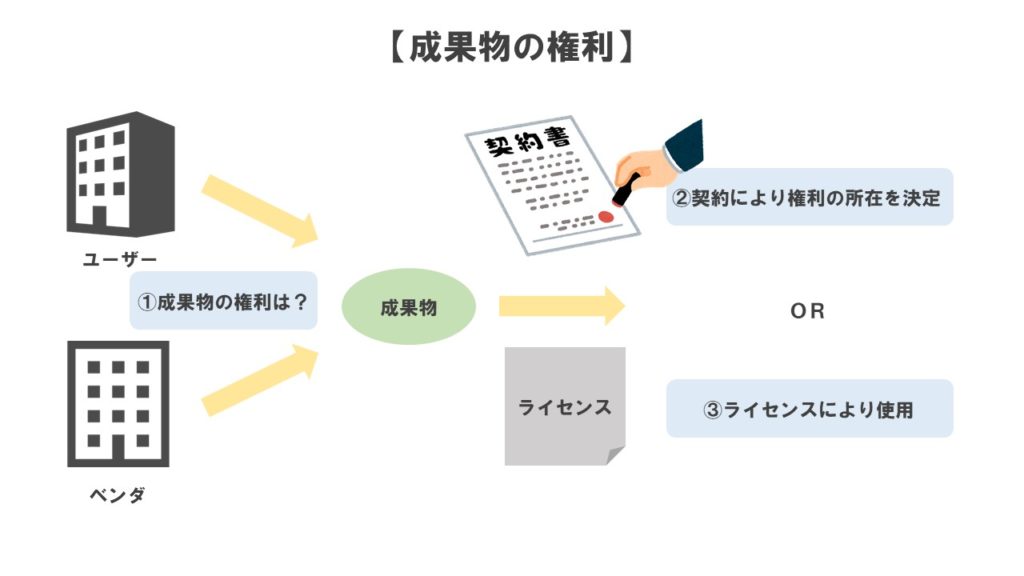
もっとも、デフォルトルールはこのとおりなのですが、「誰が権利を持つか?」の問題と、それを実際に「誰が利用できるのか?」の問題は別になる点には注意が必要です。
ベンダ・ユーザーのどちらが成果物について権利を持つにせよ、契約書上で一方が権利を持つことを認めつつも、権利者が他方に対して利用を認める(=ライセンスをする)ことで、実質的には権利がない方も成果物を利用できます。
そのため、AI開発契約における交渉過程において、ベンダ・ユーザー間で「どちらが権利を持つか」で争い、その議論が平行線になってしまうような場合には、
「権利は渡すがライセンスを受けて利用する」
という折衷案で落とすというオプションがあることを予め知り、無用な争いはなるべく回避していくことが重要です。
以上を踏まえて、AIの成果物について、具体的に誰にどういった権利が認められ、保護されるのか?を見ていきましょう。
3 成果物①:生データ

(1)誰がどのような権利を持つのか?
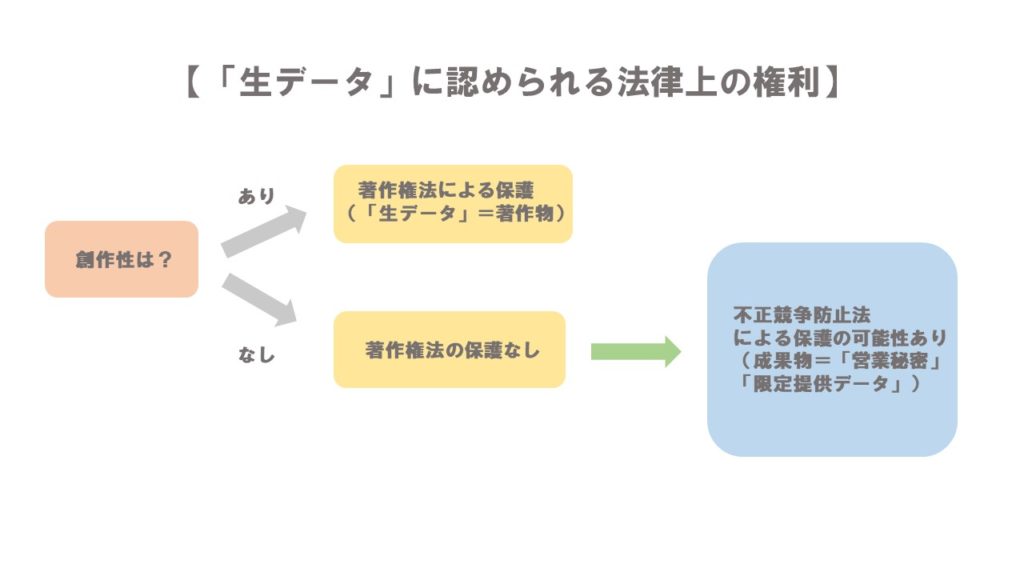
「生データ」とは、AIのプログラム学習用に特に加工をしていない単なるデータのことをいいます。まず、著作権法によってこの「生データ」が保護されるか?を検討します。
「生データ」については、例えば、気温等の客観的な事実などについては、原則として著作物ではないため、著作権法では保護されません。著作権として守られるために必要な「創作性(個性)」がないからです。
反対に、当該データ自体が写真・文章など著作物として求められる「創作性(個性)」が備わっていれば、その生データは「著作物」にあたり、データを生成した者が著作者として保護されます。
仮に、生データが著作物ではない場合でも、
- 「営業秘密」
- 「限定提供データ」
に該当する場合には、不競法によって守られます。
(2)データを集めるときの法律問題
最終的に完成される学習済みプログラムは、その基礎となる生データの質・量によってその品質が左右されます。そこで、ユーザーやベンダにとっては、いかにしてこの生データを適法に入手するかが極めて重要な課題となります。
ここで注意すべき主な法律規制は、以下の3つです。
- 著作権法
- 個人情報保護法
- プライバシー、肖像権
以下で、順番に見ていきましょう。
①著作権法
AIのシステムを開発する際には、その目的に応じた画像や動画などが収集されます。もっとも、収集された画像や動画などの中に、第三者が著作権をもっているものが含まれている場合には、注意が必要です。このような画像や動画などを自社のストレージに保存すると、著作権者がもつ複製権の侵害と判断される可能性があります。
この点、著作権法は例外的な扱いとして、「電子計算機による情報解析」を目的としている場合には、必要な限度で第三者の著作物を記録媒体に記録・翻案することができるとしています。
そのため、収集した画像や動画などの中に、第三者が著作権をもっているものが含まれているとしても、AIのシステムを開発するために必要な限度で、ストレージに保存したり、改変することが許されることになります。
②個人情報保護法
ユーザーがベンダに提供する一定の情報の中に、その情報自体からであったり、他の情報と照合することにより特定の個人を識別することができる場合には、そのような情報は個人情報保護法上の「個人情報」にあたる可能性があります。
その場合には、本人から同意を受けることなく、その情報を取得することができない場合もあります。さらに、個人情報を提供する者に対しては、提供を受けた者が目的を超えて利用しないように、提供を受けた側に秘密保持義務が課されるなどといったことを周知する義務が課されますので、注意が必要です。
③プライバシー、肖像権
AIシステムの開発のために取得するデータの中に、公道における通行人であったり、公道上の人の挙動に関するデータが含まれている場合には、その者のプライバシー権や肖像権との関係で問題となります。
この点、AIシステムの開発のためだけに限定して利用されており、かつ、取得データの一般公開が想定されていないような場合には、プライバシー権や肖像権を侵害しているものと判断される可能性は低いと考えられます。
もっとも、自分の知らないところで勝手に写真を撮られたとして、そのことを不愉快に思う人も存在するはずです。そのため、誰が見ても一見して撮影していることがわかるような表示を施すなど、一定の配慮を検討する必要があると思われます。
(3)データを提供するときの法律問題
既に見たとおり、AIの開発契約においては、ユーザーが取得した生データをベンダに提供することが典型的なフローとなります。ユーザーからすれば、自社にとって貴重な生データを適当には扱ってもらいたくないと考えるのが一般的でしょう。
そこで、ベンダとの間において、以下のように生データの取扱いなどについてしっかりとしたルールを作っておくことが必要になってきます。
- 目的外使用禁止
- 第三者提供の禁止
もっとも、目的外使用や第三者提供を禁止する旨を契約で合意していたとしても、ベンダがこのルールに違反して、目的外で使用したり、第三者に提供していることをユーザーが実際に把握することは事実上困難です。それでは、このような契約を結ぶ意味がなくなってしまいます。
そのため、たとえば、契約の中で、データの保管体制やアクセス権者の制限、さらには、これらのルールをきちんと守っているかどうかを定期的にユーザーにおいてチェックできるような規定を設けることも考えられます。
4 成果物②:学習用データセット

「学習用データセット」とは、AIが学習しやすいように、生データを加工して作られた二次データのことをいいます。
集めた生データがそのままAIの学習過程に使えるかというと、実務ではそうではない場合が多く、
- データの選別
- ノイズとなるデータの除去(クレンジング)
- 画像データであれば上下反転させたりする作業(アフィン変換)
- あえてノイズを入れることでデータ量を増やす等のデータ拡張技術(オーギュメンテーション)
といった加工や変換作業が必要になります。
こういった作業を通じて生成されたものが「学習用データセット」といわれるものになります。
これらの作業には、多くの労力・費用がかかるため、学習用データセット自体に、どういった権利が認められるのか?を検討する必要が出てきます。
(1)学習用データセットにはどのような権利が認められるか?
学習用データセットについては、基本的には著作権で保護されない生データとは違い、加工・変換といったように人の手が加わることから、著作権法に書かれた「データベースの著作物」として保護されないかが問題となります。
「データベースの著作物」として保護されるためには、
- 情報検索できるように体系的に構成されていること
- 情報の選択や構成について創作性があること
の2点が必要です。
この点、学習用データセットの作成プロセスでは、一定の目的のために大量に集められたデータの中から、単にAIが学習しやすいように配列を編集するといった単純作業にとどまらず生データに注釈(正解データ)を付す作業(アノテーション)や、先ほども説明した少量の生データに汎用性を持たせて大量の学習用データセットを作り出すための拡張技術(データオーギュメンテーション)などの作業が施されます。
こういった選択や構成に独自性(創作性)があると認められる場合には、データベースの著作物として、著作権法上の保護を受けることができます。
他方、こういった選択・構成に創作性が認められない場合には一切保護されないのでしょうか?
このケースについては、生データと同じように、その学習用データセットも
- 「営業秘密」
- 「限定提供データ」
に該当する場合には、不競法によって守られます。
なお、実務でも争いがあるのですが、著作権法などによって保護されない学習用データセットについても、限定的ではありますが、民法上の「不法行為」というルールによって保護される可能性があります。
仮に学習用データセットをパクる等の行為が不法行為と評価される場合には、学習用データセットを創作した企業などは、パクった相手方に対して損害賠償請求などを行使することができます。
(2)誰が権利を持つのか?
では、データベースの著作物として保護される学習用データセットについては、誰が権利を持つのでしょうか?
基本的に、データベースの著作物に限らず、著作権法に通底する考え方としては、創作的な表現をした主体に権利を認めます。
そのため、学習用データセットについてみると、著作権者となるのはあくまでも生データからの選択や体系的構成を組んだ者です。
単に、その者の指示や方針に従って手足のようにデータを収集しただけの者などは、自らが独自性のある創作活動をしていないことから、著作権者にはなりません。
そのため、AI開発契約において、ベンダ側のみがデータ加工をしている場合には、ベンダが著作権者となります。
もっとも、学習用データセットの作成プロセスにベンダのみならず、ユーザー企業も関与し、一緒になって加工するなどの行為をしている場合には、ベンダとユーザーの「共同著作物」として、2社が学習用データセットを「共有」することになります。
※共同著作物の場合、片方の一存で学習用データセットを利用できなくなるという制約がつきます。
(3)AI開発契約でどのように定めるべきか?
上記のとおり、学習用データセットの著作権は、原則としてベンダ側が持つことになります。
学習用データセットについては、アノテーションやデータオーギュメンテーションといった技術の重要性や、大量の労力を投下して生成されることから、ベンダ側に著作権を持たせることには合理性があります。
他方で、ユーザーとしては、学習用データセットの元データを提供していることが多く、充実したデータをどれだけ集められるか?が極めて大事なAI業界においては、ユーザー側において著作権を持ち、自由に利用できるようにしたい、と考えることも自然です。
このようにAI開発契約の文脈では、ベンダ・ユーザーの利害が一見ぶつかることから、ベンダが権利を持つというデフォルトルールにかかわらず、いずれが学習用データセットの著作権を持つのか?をめぐって争いが生じます。
そのため、両プレイヤーの利害をうまく調和させたAI開発契約書に仕上げる必要があります。
一例ですが、
-
第〇条【学習用データセットの権利の帰属等】
①原則、ベンダ側が学習用データセットの著作権を持つことを認めながら
②その後、委託報酬をユーザーがベンダに支払った時点で、ベンダからユーザーに権利移転するものとし
③ただし、データオーギュメンテーションのような生データから学習用データセットを生成するために必要な汎用的技術については、ベンダ側が依然として持ち続ける
という契約案が考えられます。
5 成果物③:学習用プログラム

「学習用プログラム」とは、学習用データセットを通じて学習し、学習済みモデルを生み出すためのプログラムの部分をいいます(通常、学習済みモデルは、この「学習用プログラム」と「学習済みパラメータ」の二つから構成されます)。
AIは、これまで説明してきた「データ」部分と、コンピュータに対する命令である「プログラム」部分でできていることから、後者のプログラムの部分についても著作権によって保護されるのか?が問題となります。
(1)学習用プログラムにはどういった権利が認められるか?
著作権法には、「プログラムの著作物」という概念が用意されており、これに学習用プログラムが当てはまる場合には、プログラム著作物として著作権が認められます。
まず、ここで議論する「プログラム」と混同しやすい、
- プログラム言語
- プロトコル
- アルゴリズム
についてこれらが著作権で保護されるのか?を確認しておきます。
「プログラム」とは、著作権法ではコンピュータに対する指令を組み合わせたものとして表現されたものと定義しています。
他方で、①プログラム言語は、プログラムを表現するための手段的なものにすぎないため、コンピュータに対する指令とはいえず、プログラム著作物にはあたりません。
②のプロトコルについても、個々のプログラムにおけるルールにすぎず、具体的な「表現」ではないことからプログラム著作物ではありません。
また、③アルゴリズムは、コンピュータに対する指令の組み合わせ「方法」にすぎず、単なるアイデアレベルのものであって具体的な「表現」とはいえないことから、これまたプログラム著作物にはあたりません。
以上との対比で、学習用プログラムが「プログラム著作物」といえるのかを検討します。
まず、深層学習(ディープラーニング)に焦点を当てて検討すると、ニューラルネットワークの構造自体は、アイデアにすぎず具体的な「表現」ではないことから、プログラム著作物としては保護されません。
ただし、AI開発の過程では、ニューラルネットワークの構造などをプログラムとして記述する必要があります。
このプログラムの記述という作業は、単なるアイデアのレベルを超えて具体的な「表現」といえます。
そして、AIのプログラムは、通常のプログラムとの対比で複雑かつ高度なものと評価され、記述の選択の幅が広く、その選択において「独自性(創作性)」が認められることが多いことから、学習用プログラムは「プログラム著作物」として著作権法によって保護される可能性が高いといえます。
また、仮にプログラム著作物に該当しない場合であっても、これまでと同じく不競法の「営業秘密」といえる場合には、同法で保護されます。
(2)誰が学習用プログラムの著作権を持つのか?
学習用プログラムがプログラム著作物として保護されるケースでは、その学習用プログラムを生成した者が著作権者として権利者になります。
この点、学習用プログラムは通常、株式会社などの「法人」という箱の中で働くAIエンジニアなどが開発することが多いです。そうすると、学習用プログラムの著作権は、実際に開発したAIエンジニア個人に帰属するように思えますがそれは誤解です。
正しくは、むしろそのAIエンジニアが所属する「法人」に原則として著作権は帰属します(これを「職務著作」といいます)。
(3)AI開発契約でどのように定めるべきか?
上記のとおり、学習用プログラムの著作権は、原則としてベンダ側が持つことになります。
この点、学習用プログラムは、ベンダ側がビジネスにおいて勝ち抜くための源泉となる技術であり、他の受託開発の案件においても汎用的に使えるものであるから、ベンダ側としては、当然著作権を自分たちの方に留保したいと考えます。
他方で、ユーザー側としては、技術的価値的に学習用プログラムと分離困難とされる学習済みパラメータ部分については、ユーザーが提供して編成された学習用データセットをベースに得られた成果物といえます。そのため、学習済みパラメータ部分、それと分離困難な学習用プログラムについても、ユーザーとしては、権利を持っておきたいと考えるのもおかしいことではありません。
そのため、ここでもまた両プレイヤーの利害をうまく調和させたAI開発契約書に仕上げる必要があります。
学習用プログラムの契約案については、理論的には3つ考えられます。
- 【A案】:学習済みモデルを(これまで解説してきたとおり)①学習用プログラムと、②学習済みパラメータ部分とに2分し、前者はベンダが、後者はユーザーが保有し、ベンダが学習用プログラムをユーザーにライセンスする案
- 【B案】:学習済みモデル(学習用プログラム+学習済みパラメータ)全体の権利はベンダが保有し、それをユーザーにライセンスする
- 【C案】:学習済みモデル全体の権利をユーザーが保有する
このうち、C案については、ベンダにおいて学習用プログラムの権利を重視していない場合に採用されうるものですが、あまり現実味がありません。そのため、実際には、プレイヤー同士のパワーバランスによって、A案かB案が選択されることになると考えられます。
それぞれの案についてAI開発契約書の一例をご紹介しておきます。
-
【A案】
第〇条(学習済みモデルの権利の帰属等)
①学習用プログラムの権利がベンダに帰属することを確認
②学習済みパラメータの権利がユーザーに帰属することを確認
③ベンダは、ユーザーに対して「非独占的or独占的」に学習用プログラムをライセンスする
④ベンダは、ユーザーの事前承認ないところで学習済みパラメータは利用できない
⑤なお書として、ベンダはユーザーに対してライセンスした範囲内では著作者人格権という著作権者の「気持ち」を守る権利は行使しないこととする
-
【B案】
第〇条(学習済みモデルの権利の帰属等)
①学習済みモデルの権利がベンダに帰属することを確認
②ただし、ベンダはユーザーに対して「非独占的or独占的」に学習済みモデルをライセンスする
③なお書として、ベンダはユーザーに対してライセンスした範囲内では著作者人格権を行使しないこととする
という契約案が考えられます。
なお、学習用プログラムは、ベンダがゼロベースで開発する場合ももちろんあるのですが、実際には「OSS(オープン・ソース・ソフトウェア)ライセンス」が多くの場合で活用されています。この場合には、ベンダ・ユーザー双方は、各OSSライセンスポリシーに従わなければいけないことに注意が必要です。
※OSSライセンスとしては、Free Software Foundation(FSF)によって作成されたGNU General Public License(GPL)などが有名です。
6 成果物⑤:学習済みパラメータ

(1)学習済みパラメータとは
「学習済みパラメータ」とは、学習用データセットを用いた学習の結果、得られたパラメータ(係数)を意味します。
学習済みパラメータは、学習用プログラムに対し学習用データセットを入力することで、自動的に調整され生成されます。
学習済みパラメータは、学習の目的にあわせて一定の調整がされてはいるものの、それ自体では単なるパラメータ(数値等の情報)にすぎません。これを学習用プログラムに組み込んではじめて、学習済みモデルとして機能するものです。
学習済みパラメータの例としてはたとえば、ディープラーニングのケースで、各ノード間のリンクの重み付けに用いられるパラメータなどが挙げられます。
(2)学習済みパラメータは著作権によって保護されるか?
著作権によって保護されるか否かは、既に説明のとおり、成果物について
- 思想・感情の表現
- 創作性(個性)
のあることが必要です。
この点、学習済みパラメータは、学習用データセットをAIのプログラムに読み込ませることで生成され、数値行列として表現されることが多いところ、著作権法では、表現物が単純な記号であることは著作物といえるか否かとは関係がありません。
あくまでも、上記①・②の基準を満たすかどうかで判断されます。
結論を先どりでいいますと、学習済みパラメータについては、争いがあるものの、学習用プログラムを通じて自動的に生み出される大量の数値行列に過ぎず、「思想・感情」を表現したものではなく、また「創作性」がないという理由で、著作物にはあたらないと考えられています。
ただし、保管状況などによっては、不競法上の「営業秘密」・「限定提供データ」に当てはまる限りで同法により保護されます。
もっとも、学習済みパラメータの数値が生成されるプロセスでは、現状の技術的到達点においては、多くのフェーズで「人」の関与が必要であることから、その点において「思想・感情」を表現している、とみて「著作物」にあたるという見解もありえることには注意が必要です。
7 成果物⑥:ノウハウ

「ノウハウ」とは、例えば、学習率、学習回数(エポック)やバッチサイズなどのハイパーパラメータをどのように設定するか?などの知見・ハウツーを意味します。
AI開発の局面では、多くはベンダ側が持つノウハウ・アイデアがあらゆるフェーズで利用されます。
例えば、生データの「収集・選択」のノウハウや、学習用データセットを構築する際の「加工」のノウハウなどです。
(1)ノウハウは著作権で保護されるのか?
このようにAI開発契約において重要なポジションを占める「ノウハウ」ですが、これは著作権によって保護されるのでしょうか?
結論として、ノウハウは単なる「情報」にすぎず、「思想感情の表現」ではないので、著作物にはあたりません。
ただし、管理されているノウハウの中には、不競法上の「営業秘密」・「限定提供データ」として保護されるものや、特許法上の「発明」に該当し、特許権が認められるケースも想定されます。
(2)権利として一切保護されない場合
ノウハウについては、上記の解説で保護されるケースを除き、一切保護されません。ユーザ企業がベンダ側のノウハウをパクったとしても法的には責任を問えません。
ただ、以上の話は契約書で何も定めなかったらそうなる、という話であって、いずれにせよノウハウの利用条件などについては、AI開発契約書の中できちんと書いておく必要があります。
特に、AI 開発では、ベンダとユーザ間での「共同作業」としての性質が強いため、開発プロセスの中で生まれたノウハウについては、両プレイヤーが「自分のものだ!」と言い合いぶつかる可能性もあります。そのため、ノウハウの権利の所在等については、AI開発契約書の中に明記し、きちんと合意しておくことが大切です。
8 小括

以上に見てきた「成果物」の権利がどういった法律で保護されるのか?について整理すると以下のとおりです。
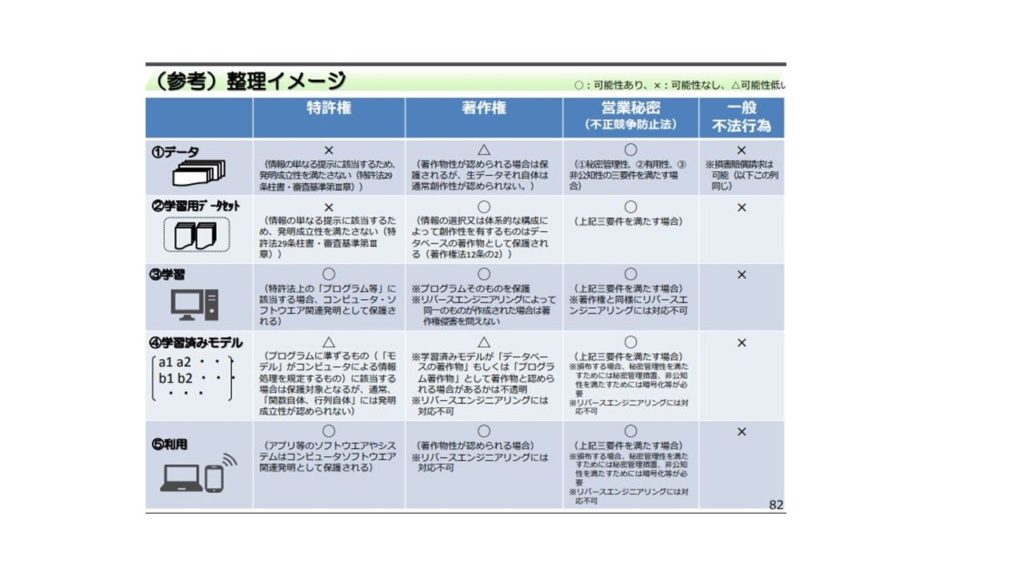
出典:「オープンなデータ流通構造に向けた環境整備」82頁(平成28年8月29日・経済産業省)
9 権利の「帰属」と「利用(ライセンス)」を使い分ける戦略法務

最後に、成果物に対する「権利の帰属」と「利用(ライセンス)条件」をうまく使い分ける戦略について見ていきたいと思います。
(1)権利の帰属
成果物に対する権利の帰属(=権利者)を契約で定めるとなると、以下の3通りしかありません。
- ベンダ
- ユーザー
- ベンダ・ユーザー共有
もっとも、成果物は、著作権の対象となるものと著作権以外の知的財産権の対象となるものとに分かれます。仮に、成果物が著作権の対象になるとするならば、ベンダ・ユーザー双方が成果物に対する権利を主張することが想定され、紛争に発展する可能性が出てきます。そのため、著作権の対象になる成果物の権利帰属者については、できるかぎり、AI開発契約の中で決めておきたいところです。
他方で、著作権以外の知的財産の対象となるものについては、契約時においてどのようなものが出来上がるかわからないことも多いことから、契約の中で権利帰属者を決めていないかぎり、成果物を創りだした者が権利帰属者になるとされています。
なお、この場合も、あらかじめ契約の中で権利帰属者を決めておくことは可能です。
このように、成果物に対する「権利帰属」の問題は、基本的には双方間の契約で定めてしまうことで解決しますが、双方が権利の帰属を譲らずにいつまでもこだわっていると、交渉は平行線のままで、双方とも競争力を失うことになりかねません。
そこで、成果物の「権利帰属」と「利用(ライセンス)」をうまく使い分けた条件をベンダ・ユーザー間で設定することができないか、という点が問題となります。
以下で、見てみましょう。
(2)利用関係
仮に、ベンダ・ユーザー間で成果物に対する権利者(=著作権者)をベンダにする旨の契約が成立しているものとしましょう。このような場合であっても、ベンダ・ユーザー間で交渉した結果、成果物をユーザーが自由に利用できるといった内容の合意が成立すれば、ユーザーにおいて実質的に成果物の権利を取得したのとほとんど同じ効果を生じることになります。
利用条件については、事業者の事業内容や規模などによってさまざまであるため、ベンダ・ユーザー間でその点に折り合いがつくようであれば、権利の帰属にこだわるのではなく、いかにして自社のビジネスに見合った利用条件を設定できるか、という点を模索した方が生産的であるともいえます。
このように、成果物をめぐっては、その権利を自社に帰属させようと躍起になりがちですが、その点にあまりこだわり過ぎることは、ベンダ・ユーザーともに得策であるとはいえません。成果物の「権利帰属」と「利用条件」とを使い分け、契約に両方の要素をうまく盛り込むことができれば、ベンダ・ユーザー双方にとって利益があるものと考えられます。
以下で、AI開発契約を結ぶ場合の注意点について確認しておきましょう。
(3)まとめ
ベンダとユーザーは、いずれもAI開発契約を結ぶ場合には、以下の点に注意するようにしましょう。
- AI開発契約の特殊性
- AI開発契約の形式
- 開発プロセス
- 成果物の権利とその帰属
以下で、簡単に見てみましょう。
①AI開発契約の特殊性
AI開発は、開発してみないとどのような「成果物」ができるのかわかりません。そのため、ベンダとしては性能を保証することができません。
このようなAI開発独自の特殊性を念頭に置いておかなければなりません。
②AI開発契約の形式
AI開発契約には、
- 成果物をコミットする「請負契約」
- 成果物をコミットしない「準委任契約」
とがあり、採用する形式により契約の性質に違いが出てきます。
なお、通常は成果物をコミットしない「準委任契約」となります。
③開発プロセス
開発プロセスには、
- 「ウォーターフォール型」
- 「アジャイル型」
とがあります。
「ウォーターフォール型」とは、システムの開発をいくつかの工程に分けて順に段階を踏む手法です。
「アジャイル型」とは、設計などの変更を前提として、おおよその設計だけで開発を開始し、実装とテストを繰り返すことにより、徐々に開発を進めていく手法です。
どちらの開発プロセスを採用するかで、契約内容にも違いが出てきます。
なお、通常は「アジャイル型」となります。
④成果物の権利とその帰属
以下の成果物について、ベンダ・ユーザーのどちらがどういった権利を持つのか、という点を確認しておく必要があります。
- 生データ
- 学習用データセット
- 学習用プログラム
- 学習済みモデル
- 学習済みパラメータ
- ノウハウ
こういった点を契約で定めておくことにより、無用なトラブルを回避することができます。また、この点に関連して、これらの成果物を「誰が利用できるのか?」ということも別に契約で定めておくことが重要です。
10 小括

AI開発契約のプロセスで生まれる「成果物」には、権利の帰属や利用条件などといったように、さまざまな問題が付着しています。
こういったAI開発の特殊性をきちんと把握し、AI開発契約を結ぶ場合にはどのような点を検討すべきか(=契約書に盛り込むか)?といったことをしっかりと詰められているかどうかが大変重要になってきます。
そのため、AI開発契約を結ぶ際には、以上のような観点から、AI開発契約における検討事項をしっかりと理解し、自社にとって最適な契約を結ぶことが大切です。
11 まとめ
これまでの解説をまとめると、以下のようになります。
- AI開発においては、開発してみないと「成果物」としてどのようなものができるかわからないため、ベンダ側は「性能保証」が困難である
- AI開発契約のプロセスで生まれる「成果物」は、主に①生データ、②学習用データセット、③学習済みモデル、④ノウハウの4つに分けられる
- 基本的に、成果物の権利は成果物を作った人が持つ
- 成果物について、「誰が権利を持つか?」の問題と、「誰が利用できるのか?」の問題は別の問題である
- 成果物が法律で保護されるかどうかは、成果物が①著作権、②特許権、③営業秘密等(不正競争防止法)にあたるかどうかを検討する
- 生データを入手する際に注意すべき法律規制は、①著作権法、②個人情報保護法、③プライバシー、肖像権の3つである
- 生データを提供するときの法律問題として、①目的外使用禁止、②第三者提供の禁止といった点が挙げられる
- 学習用データセットの著作権は、原則としてベンダ側がもつ
- 学習用プログラムの著作権は、原則としてベンダ側がもつ
- 学習済みパラメータは、著作物にあたらないと考えられている
- ノウハウは著作物にあたらない
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
現在は、企業法務を中心とした弁護士業務と、一橋大学大学院ソーシャル・データサイエンス研究科(M1)における研究の2軸で活動しています。 弁護士としては、IT・ゲーム・AI・FinTech分野を中心に、契約・利用規約、知的財産、個人情報保護、資金決済・金融規制、企業法務などを取り扱っています。 大学院では、法令工学を基盤として、法令データの構造化や生成AI・データサイエンスを活用した法情報処理に関する研究に取り組んでいます。







