












AIの「派生・蒸留モデル」の生成は著作権侵害?弁護士が5分で解説

はじめに
昨今、AIの分野における発展には目覚ましいものがありますが、さらなる試みとして、学習済みモデルの精度向上やAIの効率化などを目指した「派生モデル」や「蒸留モデル」を作成することが考えられます。
「派生モデル」は既存の学習済みパラメータを改変することにより作成され、「蒸留モデル」は既存のAIの入力値と出力値を用いて学習させるといった特徴があります。
このように、いずれのモデルにおいても、既存のモデルを用いて作成されるという特徴があるため、このようなモデルを作成することが著作権侵害にならないか?ということが問題となります。そして、派生モデルや蒸留モデルを作ろうと計画している事業者にとっても、この問題が大変強い関心事となるのです。
そこで今回は、AIの「派生モデル」・「蒸留モデル」を作成することが著作権侵害にあたるのか?という問題について、ITに強い弁護士が解説します。
1 AIの成果物の種類

まずは、AIが生み出す成果物の種類について確認しておきましょう。
AIが生み出す成果物は、主に以下の7つに分けられます。
- 生データ
- 学習用データセット
- 学習用プログラム
- 学習済みパラメータ
- 学習済みモデル
- 派生モデル
- 蒸留モデル
(1)生データ
「生データ」とは、AI開発を目的として個人・事業者・研究機関などから一次的に取得され、読み込むことができるように最低限の変換・加工処理のみがなされているデータのことをいいます。
たとえば、スーパーマーケットの売上予測を立てるAIを開発する場合であれば、過去の曜日ごとの客数、時間帯ごとの購買層、商品の入れ替わり、などといったさまざまなデータが必要となります。これらをデータベースに読み込ませる形に変換・加工しただけのデータが「生データ」です。
(2)学習用データセット
「学習用データセット」とは、大まかな選別によってのみ集められた生データを、AIの学習が効率的になるように加工した二次的なデータをいいます。
具体的には、外れ値や欠陥値を取り除いたり、欠損しているデータの穴埋めをしたりといった方法で加工されます。
先ほどのスーパーマーケットの例でいうならば、平日に近隣で大きなイベントが単発的に開催された日の売上データは、一般的な平日の売上予測との関係では特異な数値となるため取り除かれることになります。
(3)学習用プログラム
「学習用プログラム」とは、AIが人の手を離れて発展的に学習していくためのプログラムのことをいいます。生データを加工して作られた学習用データセットの中に規則性を見出し、その規則を表すためのプログラムを組むことでAIは将来において自発的に学習を進めていくことができるようになります。
(4)学習済みパラメータ
「学習済みパラメータ」とは、学習用データセットを用いてAIが学習した結果、得られた係数を指します。それ自体では大きな意味を持ちませんが、係数を調整することで入力値と出力値の誤差を小さくするために利用されます。
スーパーマーケットの例でいうならば、天候と客数の間にある関係性の強さを調整していくことがパラメータ調整となります。午前中は晴れていたものが夕方にかけて雨模様になるに連れて、どれほど客数が減るのかといったことを係数として数値化し、調整することでより正確な予測を立てられるようになるのです。
(5)学習済みモデル
「学習済みモデル」とは、学習済みパラメータが組み込まれた推論プログラムを指します。スーパーの例でいうと「10月1日の売上予測」を実際に推測していくためのプログラムを指します。
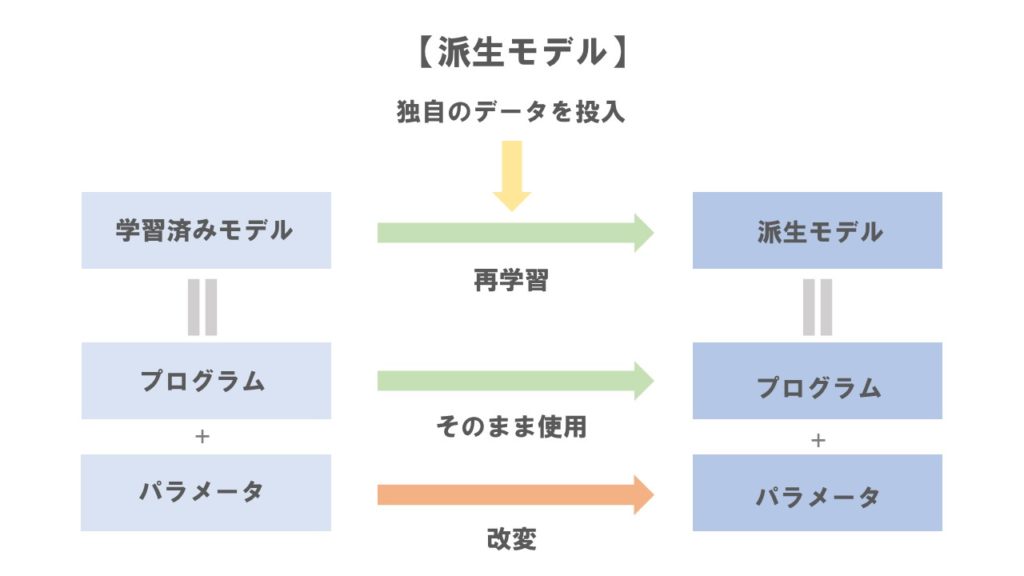
(6)派生モデル
「派生モデル」とは、既存の学習済みモデルにさらなる学習をさせることによって作成された新しい学習済みモデルのことをいいます。派生モデルは、学習済みモデルのパラメータ部分を改変することによって作成される新しい学習済みモデルであり、プログラム部分はそのままの状態で使用されます。
(7)蒸留モデル
「蒸留モデル」とは、既存の学習済みモデルを利用して得られる入力値と出力値から推論プログラムを組むことにより作成された新たな学習済みモデルのことをいいます。
スーパーの例でいうと、売上予測を立てるために生成された学習済みモデルは、「10月1日」と入力すると、売上予測として「1,000万円」、「10月2日」と入力すると、売上予測として「950万円」というように、結果が出てきます。
蒸留モデルを生成する場合、生データを取得するところから始める必要はありません。入力値に対して既存のAIと同じ出力値を出すように学習させていくことにより生成されます。
そのため、蒸留モデルは蒸留の基盤となった既存のAIよりも構造をシンプルにしやすくなり、そこから、開発コストを抑えたり、動作が早くなるというメリットにつながるのです。
以上のように、AIが生み出す成果物にはさまざまな種類がありますが、その中でも「⑥派生モデル」と「⑦蒸留モデル」は、いずれも既存のモデルを用いて作成されるという点に特徴があります。
今回は、この「派生モデル」と「蒸留モデル」にフォーカスして、それぞれにおける法律上の問題点について、以下で見ていきたいと思います。
2 「派生モデル」の作成における法律上の問題点

「派生モデル」とは、既に見たように、既存の学習済みモデルにさらなる学習をさせることによって作成された新しい学習済みモデルです。
この派生モデルを作成する際に法律上問題となるのは、
- 「翻案権」の侵害になるか?
- 「二次的著作物」にあたるか
という2点です。
3 問題点①:「翻案権」の侵害となるのか?

「翻案権」とは、既存の著作物を基にして、新たな著作物を創作できる著作権法上の権利です。たとえば、ドラえもん(既存の著作物)をアニメ化する場合などがこれにあたります。
派生モデルは、既存の学習済みモデルのパラメータ部分を改変することによって作成されるため、既存の学習済みモデルの著作権者から許可を受ける必要があるのではないか?そのような許可なしに派生モデルを作ると「翻案権」を侵害することになるのではないか?ということが問題になるのです。
以下では、改変する学習済みパラメータが「プログラム著作物」にあたるケースと「データベース著作物」にあたるケースとに分けて見ていきたいと思います。
(1)学習済みパラメータが「プログラム著作物」のケース
「プログラム著作物」とは、著作権法上の「プログラム」に該当し、そのプログラムに「著作物性」がある著作物のことをいいます。
-
【プログラム】
- コンピュータなどを機能させて一の結果を得ることができるようにこれに対する指令を組み合わせたものとして表現したものを指すとされています。
- 思想や感情を創作的に表現したものであって、文芸、学術、美術又は音楽の範囲に属するものであることを意味します。
【著作物性】
以上の2つの条件をいずれもみたす学習済みパラメータは、「プログラムの著作物」となります。
プログラムの著作物の複製物を所有している人は、自分でコンピュータで使うために必要と認められる範囲で、プログラムの著作物を複製(コピー)したり翻案することができます。
そのため、学習済みパラメータが「プログラム著作物」にあたる場合において、学習済みパラメータの複製物を所有している人は、一定の範囲で、学習済みパラメータを翻案することができます。
もっとも、ここで注意しなければならないのは、以上のような複製・翻案を認められているのは、プログラム著作物の複製物を所有している人に限られているという点です。
複製物をレンタルしているだけであったりライセンスを受けているだけの人は、この複製・翻案は認められません。
次に、プログラム著作物は「必要と認められる範囲」で翻案できることとなっているため、「必要と認められる範囲」が具体的にどのようなことを意味しているのかが問題となります。
この点は、たとえば、コンピュータを操作するにあたり当然に求められる複製、インストール、または、機能を向上させるための複製・翻案などが「必要と認められる範囲」の翻案にあたると考えられます。
AIの精度を高めるために学習済みパラメータを改変することは、機能を向上させるための翻案といえ、必要と認められる範囲の翻案にあたり違法ではないと考えられます。
もっとも、学習済みモデルをまったく別の用途に変えてしまうような場合には、そのためのパラメータの変更が「必要と認められる範囲」を超えていると判断される可能性がありますので、注意が必要です。
以上のように、学習済みパラメータが「プログラムの著作物」にあたるケースでは、その複製物を所有している人が派生モデルを作成したとしても、それは機能を向上させるためであり、「必要と認められる範囲」の翻案であるため、翻案権を侵害することにはならず合法と考えられます。
(2)学習済みパラメータが「データベース著作物」のケース
「データベース」とは、数値や図形などといった情報の集合物であって、それらの情報をコンピュータを用いて検索することができるように体系的に構成したものをいいます。そして、このデータベースに創作性が認められれば、「データベース著作物」にあたります。
「データベース著作物」に関しては、上に見た「プログラム著作物」のように、所有者が一定の範囲で複製・翻案することが許されていません。
そのため、改変をした部分に「情報選択や体系的構成」という観点で見た場合の創作性があるかどうかを検討する必要があります。
データベース著作物について、改変をした部分に以上のような創作性がある場合、著作権侵害が成立し、違法となります。
学習済みパラメータにおける「情報選択や体系的構成」は、プログラム部分に依存することが一般的です。
そのため、プログラム部分は変えずに、加工データを追加することで学習させた結果、学習済みパラメータ部分が改変した場合には、学習済みパラメータにおける「情報選択や体系的構成」の創作性がある部分を改変したことにはならないため違法でないと考えられます。
このように、学習済みパラメータが「データベース著作物」にあたるケースでは、改変をした部分に一定の観点から見た創作性があるかどうかが重要なポイントとなります。
創作性が認められれば、データ著作物に対する著作権侵害が成立し、違法になるものと考えられます。
以上は、主に権利侵害にあたるかという観点で見てきましたが、「派生モデル」における法律上の問題点はこれだけではありません。
以上とは別の観点から、派生モデルが「二次的著作物」にあたるかどうかという点も検討しなければなりません。
4 問題点②:「二次的著作物」にあたるのか?

「二次的著作物」とは、既存の著作物を翻案することにより創作した著作物のことをいいます。
派生モデルがこの「二次的著作物」にあたる場合は、派生モデルに対しても原著作権者(基となった著作物の著作権者)の権利が及ぶことになるため、問題となります。
もっとも、原著作権者が派生モデルに対してこのような権利を及ぼすためには、基となったパラメータに著作権があることが必要です。
基となったパラメータに著作権があり、さらに以下の2つの条件をみたしていれば、派生モデルは二次的著作物にあたり、原著作権者の権利が派生モデルに及ぶことになります。
- 基となったモデルと派生モデルの間で、表現上の本質的な特徴が同じであること
- 派生モデルにおいて基となったモデルの本質的な特徴を直接感じ取ることができること
この点、派生モデルにおいては、パラメータ部分(係数)が大きく変えられることが想定されます。そのため、基となったモデルと派生モデルの間で、表現上の本質的な特徴が同じであるとはいえず、また、派生モデルから基となったモデルの本質的な特徴を直接感じ取ることができるとまではいえないと考えられます。
このような場合、派生モデルは二次的著作物にあたらず、原著作権者の権利は派生モデルには及びません。
もっとも、派生モデルは先にも見たように基となったモデルのプログラム部分をそのまま使用します。
そのため、原著作権者はプログラム部分の著作権を根拠に、派生モデルについての利用方法を決めておくなど、パラメータ部分に対して一定のコントロールを効かせることは可能であると考えられます。
他方で、プログラム部分とパラメータ部分の権利者が異なる場合には、プログラム部分について著作権をもたないパラメータ部分の権利者が、派生モデルに対して著作権を及ぼすことは困難だと考えられます。
この場合、パラメータ部分に著作権が認められるかどうかが不明であることに加え、仮に著作権が認められたとしても、上で見たように、派生モデルのパラメータ部分が二次的著作物として認められる可能性は低いと考えられるためです。
以上のように、派生モデルにおいて、二次的著作物にあたるための上記2つの条件をみたす可能性は低く、二次的著作物にあたらない可能性が高いと考えられます。
そのため、原著作権者は自分の権利を派生モデルに及ぼすことは困難だと考えます。
5 「蒸留モデル」の作成における法律上の問題点

「蒸留モデル」とは、既に見たように、既存の学習済みモデルの入力値と出力値を利用して、そこからプログラムを新たに作成していく手法により作成されたモデルです。

既存の学習済みモデルを利用するという意味では蒸留モデルも派生モデルと同じです。
そのため、このような手法で新しいモデルを作成することが既存の学習済みモデルにおけるプログラム部分の著作権を侵害することにならないか?ということが問題となります。
この点、著作権との関係で特に問題となるのは、蒸留モデルが「複製」にあたるかどうかという点です。
「複製」とは、ある物を真似て同じ物を作ること(=コピーすること)をいいますが、著作権者には著作権に含まれる権利の一つとして、著作物を無断で複製させないという権利(=複製権)が与えられています。
そのため、蒸留モデルが「複製」にあたる場合には、複製をすることについて原著作権者の許可を受けていなければ、「無断複製」となり著作権侵害にあたります。
著作権法上の「複製」といえるためには、蒸留モデルが既存の著作物に加工を入れて再製されていることが必要であり、独創的に作成したものは再製にあたらないとされています。
そのため、複製権を侵害したといえるためには、
- 他人の著作物であることを認識していること
- 他人の著作物を自分の作品の中で使い、他人の著作物に依拠していること
という2つの条件をみたしていることが必要です。
たとえば、同じ表現が使われている著作物であっても、他人の著作物の存在を知らずに独自に作品を創ったような場合には、上の①、②のいずれもみたさないことになり、複製権を侵害したことにはなりません。
AIにおける蒸留モデルについて見てみると、この手法で使われているのは、あくまで既存の学習済みモデルにおける入力値と出力値のみです。
そのため、既存の学習済みモデルが他人の物であることを認識していても(条件①)、既存の学習済みモデルのプログラムに「依拠」しているとはいえず、条件②をみたしませんので、複製権を侵害しているとはいえず、合法となります。
以上のように、蒸留モデルは、著作権に含まれる権利の一つである「複製権」との関係で問題となりますが、利用しているのが既存の学習済みモデルにおける入力値と出力値のみであることから、他人の著作物に依拠しているとはいえず、複製権侵害が成立する可能性は極めて低いと考えられます。
6 小括

AIは複雑な方法で構築され、複雑な構造を持つため、著作権侵害にあたるかどうかを検討する際にはAIから生み出される成果物についての理解も必要です。
派生モデルや蒸留モデルを作成する際には、既存の学習済みモデルのどの部分に著作権があるのかということを理解しておく必要があります。既存の学習済みモデルのプログラムやパラメータに著作権が認められない場合は、そこから派生モデルや蒸留モデルを作成しても問題にはなりません。
また、派生モデルと蒸留モデルについて、独自の問題点を正確に理解したうえで、モデルを作成する際には、その問題点に留意して、著作権を侵害することがないように作成することが重要です。
7 まとめ
これまでの解説をまとめると、以下のとおりです。
- 「派生モデル」とは、学習済みモデルをさらに学習させることで作成された新しい学習済みモデルである
- 派生モデルを作成する際には、①「翻案権」の侵害になるか、②「二次的著作物」にあたるか、が問題となる
- 派生モデルが「翻案権」の侵害となるのか?という問題は、学習済みパラメータが①プログラム著作物のケースと②データベース著作物のケースとに分けて考えるのが有益である
- 派生モデルが「二次的著作物」といえるためには、基とパラメータに著作権があることを前提に、①両者間において、表現上の本質的な特徴が同じであること、②派生モデルにおいて基となったパラメータの本質的な特徴を直接感じ取ることができることが必要である
- 「蒸留モデル」とは、学習済みモデルにおける入力値と出力値を利用してプログラムを新たに構成することで作成される学習済みモデルである
- 蒸留モデルは著作権に含まれる権利の一つである「複製権」との関係で問題となる
- 複製権を侵害したといえるためには、①他人の著作物であることを認識していること、②他人の著作物に依拠して、自分の作品の中で他人の著作物を使うこと、が必要である
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
現在は、企業法務を中心とした弁護士業務と、一橋大学大学院ソーシャル・データサイエンス研究科(M1)における研究の2軸で活動しています。 弁護士としては、IT・ゲーム・AI・FinTech分野を中心に、契約・利用規約、知的財産、個人情報保護、資金決済・金融規制、企業法務などを取り扱っています。 大学院では、法令工学を基盤として、法令データの構造化や生成AI・データサイエンスを活用した法情報処理に関する研究に取り組んでいます。







