












AI開発契約の交渉で注意すべき7つのチェック項目を弁護士が解説!

はじめに
AIを開発することで事業が展開しやすくなるのではないかと感じている人も多いと思います。ただ、AIエンジニアを抱える企業は少なく、多くの場合、AIベンダに開発を委託していますが、この際に必要となる取り決めがAI開発契約です。
ベンダとしては、その契約で学習用プログラムなどの権利が企業側に移転してしまわないかといった不安を抱え、反対に、企業としては、お金を払ってるわけだし学習済みモデルをはじめとした「成果物」の権利を取得したいと考えますよね。
ところが、この双方の思惑をAI開発契約のプロセスでどのように相手方に伝え、具体的にどういった点をAI開発契約書に落とし込めばいいのか、分からない事業者が大半なのではないでしょうか。
そこで今回は、主にAI開発契約を結ぼうと思っている事業者向けに、AI開発契約の締結に向けた交渉で注意すべき7つのポイントを、ITに詳しい弁護士が説明していきます。
1 AI開発契約とは

「AI開発契約」とは、ユーザがベンダにAI技術に関するソフトウェアの開発を委託する際に締結する契約のことです。
以下は、AI開発契約のフローを示した図です。

AI開発契約は、以下の5つのプロセスを踏むことになります。
- ユーザが、生データをベンダに提供する
- ベンダが、学習用プログラムを開発する
- ベンダが、学習用データセットを作成する
- ベンダが、学習用プログラムに学習用データセットを入力する
- 学習済みモデルが生成される
↓
↓
↓
↓
このように、AI開発のフローは、通常のシステム開発とは全く異なります。次の項目で、通常のシステム開発とAI開発の違いについて、具体的に見ていきたいと思います。
2 通常のシステム開発とAI開発の違い

通常のシステム開発とAI開発の違いについて、以下の図を使って確認してみましょう。
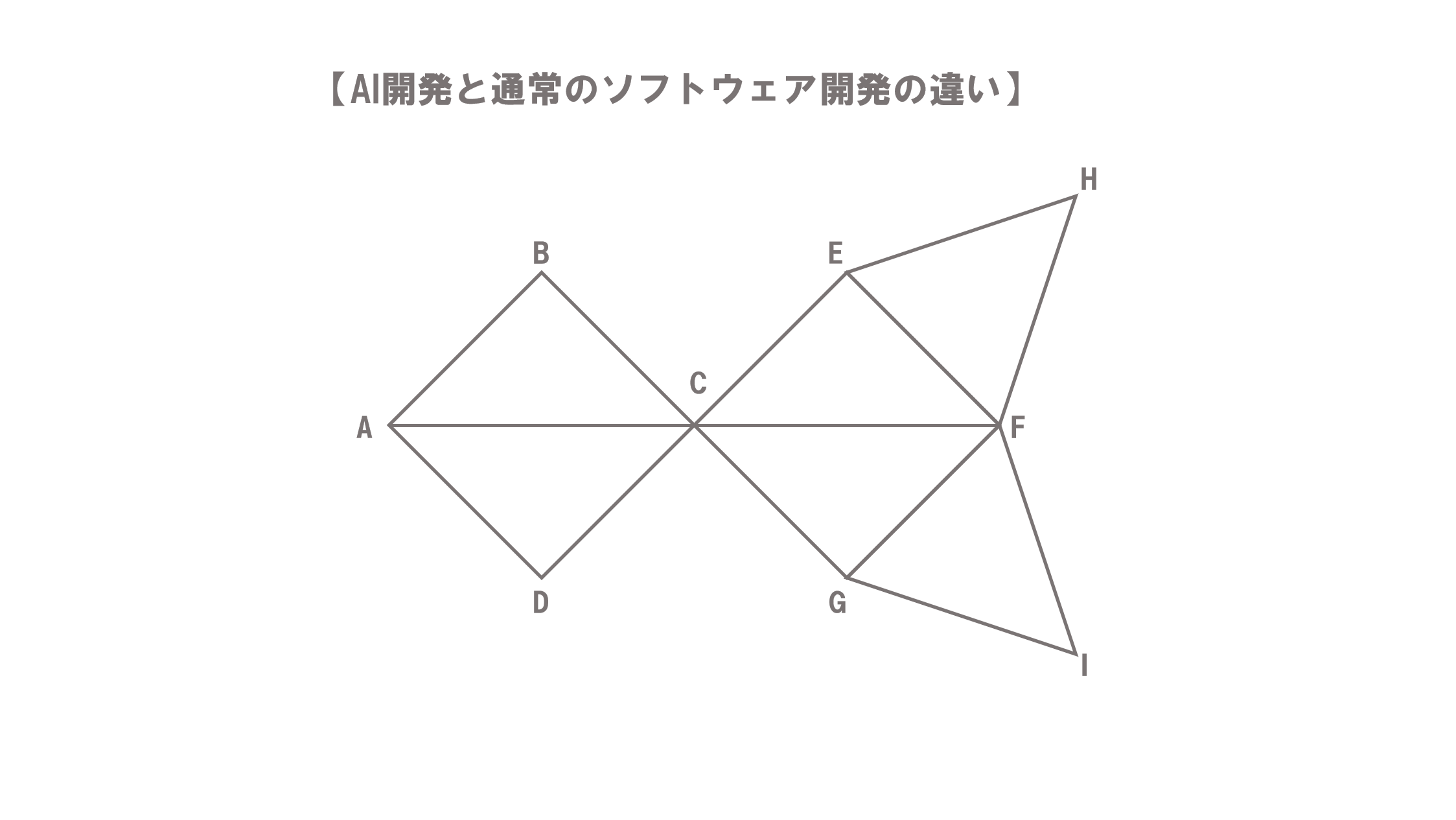
AI開発と通常のシステム開発の違いについて、Aが開発のスタート地点で、Fが開発完了のゴールだとします。
(1)通常のシステム開発
通常のシステム開発では、AからFの地点に向かって開発を行うには、「Cに行く必要がある、ならば、まずはAからCに進み、CからFに進もう」といった考えで開発が行われます。そのため、Fというゴールに向かって直線的に開発を進めることになります。
(2)AI開発
AI開発では、AからCに行く3通りの方法とCからFに行く5通りの方法を幾通りにも組み合わせたものを順路データとして用意します。
加えて、実際に人間がどのような手順を採用したかという行動科学的な統計データも用意し、データに組み込みます。このように、極めて多くのデータを取り込むことで、データの傾向を読み取り、最適なルートを導きだす形態で開発されます。
もっとも、取り込んだデータにはAからFに進む際に、迷ってしまったり、その結果Fにたどりつけなかったサンプル(外れ値)が含まれます。そのため、開発する前の段階では、どのようなものができるか分からないといった性質があります。
このようなAI開発の特質を踏まえて、経済産業省のガイドラインでは、以下のように開発プロセスを分割する「探索的段階型」の開発方式が推奨されています。
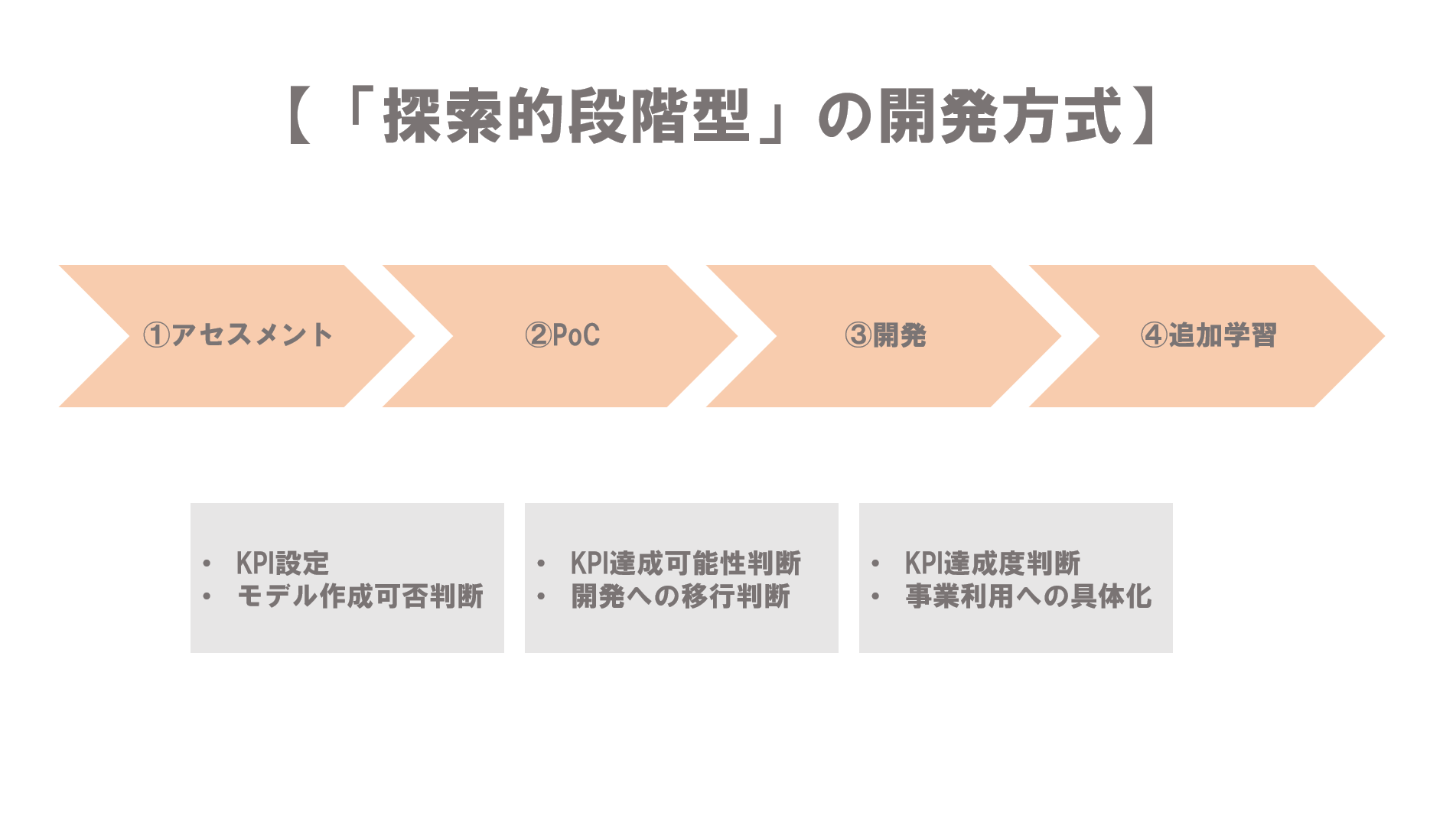
「探索的段階型」は、AI開発を以下のように
- アセスメント段階
- PoC段階
- 開発段階
- 追加学習段階
という4つの段階に分けて考えます。
①アセスメント段階
「アセスメント段階」とは、ユーザ・ベンダ間で秘密保持契約(NDA)を結んだ上で、ユーザが準備する一定のデータを基礎にして、学習済みモデルが作成可能かを判断する(モデル作成可否判断)段階のことをいいます。
アセスメント段階では、ユーザ・ベンダ間で通常のシステム開発とAI開発の構造の違いへの共通認識を構築することも重要です。また、どのような課題を達成していくかを決定していく(KPI設定)ことが重要になってきます。さらに、AI開発で生成された学習済みモデルをユーザがどのように事業に活用していきたいのかを具体化することで、実際にどのようなデータが必要となるのかを検討します。そして、必要なデータをきちんと確保できるのかをユーザ・ベンダ間で検証することになります。
②PoC段階
「PoC段階」とは、「概念実装(Proof of Concept)」を行うフェーズで、ユーザ・ベンダが用意する生データに基づいた学習用データセットを用いて、学習済みモデルを生成できるかどうかを検証する段階のことをいいます。具体的には、生データの一部を使い、試作的に学習済みモデルを作成することで、ユーザが求める精度のAIが開発可能かを判断することになります。
試作の学習済みモデルを生成することで、KPIが達成できそうなのかどうかも併せて判断します。
③開発段階
開発段階では、実際に学習用データセットを用いて学習済みモデルを生成します。
④追加学習段階
「追加学習段階」では、ベンダが生成して納品した学習済みモデルに追加の学習用データセットを読み込ませることで、さらに精度をあげたり、最新の情報にも対応できるようにする段階のことをいいます。追加学習は、学習済みモデルを生成したベンダが実施することもありますが、別のベンダが対応することもあります。
このように、AI開発は、開発のプロセスを4つに分割し、その都度、状況を把握しながら開発を進めていく「探索的段階型」が推奨されています。
以上が、AI開発のフローとなりますが、実際に取り交わすAI開発契約の契約形態はどのように設計すべきでしょうか。
ポイントとなるのは、ベンダにおいてAIの成果物を完成する義務を負う「請負契約」として設計するのか、それとも、プロフェッショナルとしての合理的努力をしていればよく、結果にコミットする必要がない「準委任契約」なのか? という点です。
3 請負契約とふたつの準委任契約

AI開発契約を締結する際に使われる契約には大きく分けて以下の2つの種類があります。
- 請負契約
- 準委任契約
(1)請負契約
「請負契約」とは、ユーザからシステム開発を受けたベンダが、学習済みモデルの生成につき完成義務を負い、ユーザがベンダに仕事の完成に対する報酬を支払うことを約束する契約です。請負契約を締結した場合、完成した物に一見してすぐには分からない欠陥(=瑕疵)があることが明らかになった場合、修補などで対応する責任(=瑕疵担保責任)が生じます。
通常のソフトウェア開発契約で頻繁に利用される契約で、完成物の具体的な性能が想定され、実現可能と考えられている際に、適した契約形態です。
このように、請負契約ではベンダが「完成義務」を負担することになるため、ベンダとしてはなるべくこの請負契約ではなく、結果へのコミットが必要ない「準委任契約」を選択したいところです。
反対に、ユーザとしては、ベンダに完成義務を負担させたいので、AI開発契約は請負契約として構成したいところです。
(2)準委任契約
「準委任契約」とは、一定の事務処理をベンダに委託する際に用いられる契約です。
仕事を依頼する、という点では請負契約と同じですが、ベンダは依頼された事項を達成するために合理的な努力をすればよく、仕事の完成義務を負担しない点が特徴です。
準委任契約には、以下の2種類があります。
- 履行割合型
- 成果完成型
①履行割合型
「履行割合型」とは、「事務処理の労務に対して報酬が支払われる」契約を指し、提供した労働時間や作業の工数に応じて報酬が支払われるものです。
そのため、ベンダによるソフトウェア開発が成功しなくとも、開発に割いた時間や作業の工数に応じて、ユーザは報酬を支払う必要があります。
②成果完成型
「成果完成型」とは、「事務処理の結果として達成された成果に対して報酬が支払われる」契約を指し、AI開発が達成された場合に報酬を支払うことになるものです。
成果完成型では、たとえ、ベンダにおいて多くの労働時間や作業の工数を割いていても、成果がまったくなければ報酬は支払われないことになります。AI開発の場合、ベンダが学習済みモデルを生成できなかった場合には報酬も発生しません。
このように、AI開発契約を「請負契約」と構成すると、ベンダには仕事の完成義務と瑕疵が発生した場合に補修や賠償をする必要があります。そのため、ベンダとしては請負契約の設計は避けたいですが、ユーザとしてはベンダに完成義務を負わせた方が有利であるため、請負契約としたいところです。
他方、「準委任契約」は、作業の工数などに基づいて報酬が支払われたり、成果物を完成させた際に報酬が発生する契約形態です。
ベンダとしては、この方式のほうが都合がよくなります。
実際のAI開発では、ベンダの意向や「実際に開発をしてみないとどのようにアウトプットされるのか見通しが立ちにくい」というAI開発契約の性質を考慮して、主に準委任契約が使われる例が多いです。
次の項目からは、「学習済みモデル」といったAI開発の成果物ごとに、契約の締結に向けた交渉のポイントを見ていきたいと思います。
4 AI開発契約における交渉のポイント

AI開発契約における交渉のポイントは、以下の7つの成果物ごとに整理しましょう。
- 生データ
- 学習用データセット
- 学習用プログラム
- 学習済みモデル
- 学習済みパラメータ
- 推論プログラム
- ノウハウ
(1)生データ
「生データ」は、多くの場合ユーザが資金的・時間的コストを投下して収集・蓄積したもので、その中には企業の営業秘密が含まれている場合もあります。そのため、生データを提供する側(多くの場合ユーザ)は、生データの取り扱いについて不正に流用されることがないよう、契約でハッキリと禁止条項を設ける必要が生じます。
仮に、ベンダが生データの二次利用を望む場合は、ユーザとしては利用目的・時期・範囲・対価や利用条件を十分協議し、契約によって明確に定める必要があります。
生データは公に知られていない販売方法や営業的・技術的に価値のある情報(=営業秘密)などが含まれる場合があるため、その取り扱いについて、しっかりと取り決める必要があります。
(2)学習用データセット
学習用データセットについては、以下の3点に注意する必要があります。
- 定義の明確化
- 再委託の可否
- 権利帰属と利用条件
①定義の明確化
「学習用データセット」という言葉は多義的に使われるため、定義に関する双方の認識をきちんとすり合わせたうえで、契約書にも明記すべきです。
学習用データセットの生成は、学習用に生データを整形することですが、具体的には、外れ値の除去や、正解データの付与、または別のデータの付加という方法で行われます。
実務上、生データと正解データが一体になったものを学習用データセットと呼ぶ場合もあれば、オーギュメンテーションという生データに操作を加えて水増ししたデータを含むこともあり、生データと学習用データの区別が曖昧な場合もあります。そのため、契約において、学習用データセットの定義を明確にすることが必要になります。
②再委託の可否
学習用データセットの生成には多くの労力を割かなければならないため、ベンダとしてはこの作業部分をアウトソースしたいという考えが生まれます。
他方で、学習用データセットの内容や品質は、学習済みモデルの性能に大きな影響を及ぼします。そのため、ユーザとしては学習用データセットの生成を別のベンダに勝手に再委託されるのは勘弁だと考えることもあるでしょう。
この点、学習用データセットを生成する際には、生データに情報を付け加える作業(=アノテーション)が行われます。
「アノテーション」とは、たとえば、「生」という漢字に「(ⅰ)植物の芽が出ること、(ⅱ)生まれること、(ⅲ)物事が起きること」といった意味情報をタグ付けしていくような作業のことをいいます。この作業は、学習済みモデルの生成にとって極めて重要なプロセスですが、単純ながらも多大な労力が必要となることもあるため、ベンダが第三者への再委託を希望することがあります。
ユーザとしては、学習用データセットの重要性から、自社の承諾なくベンダが第三者に再委託できるようにするのか、それとも承諾がない限り再委託できない、という形にするのかを決めておいた方がよいでしょう。
③権利帰属と利用条件
学習用データセットを生成するには、生データを収集・蓄積し、生データに一定の処理・加工を施す必要があります。とりわけ、処理・加工の作業には、多くの費用と労力が投下されます。そのため、生データの処理・加工が、学習済みモデルの生成における工数の大半を占めることもあります。そのため、学習済みモデルだけでなく、学習用データセットの権利がいずれに帰属するのか? どのような利用条件とするか?といった点が重要な問題となります。
この点、学習用データセットの権利帰属や利用条件を決めるにあたっては、ユーザ・ベンダ双方の学習用データセット生成への貢献度(支出したコスト、実際の作業の工数など)や生データの性質などが基礎になるものと考えられます。
例えば、学習用データセットの生成過程において、生データを処理・加工するためには、希少性の高いノウハウが用いる必要性が大きいといえます。
このように希少性の高いノウハウをもっており、そのノウハウにより生成されると見込まれる学習用データセットの価値が高いほど、学習用データセットの生成をした者が交渉を優位に進めやすいということがいえます。
また、生データに、営業上の秘密性が高い情報が含まれている場合には、契約の目的を超えて学習用データセットを利用することを制限する反面、学習用データセットの生成に投下された費用などは別途調整するということも考えられます。
このように、契約に向けた交渉では、まずは、学習用データセットの定義をきちんと特定することが重要です。そのうえで、ユーザやベンダが、どのような形で学習用データセットの生成に関わるのか、また、生データの重要性なども加味したうえで、権利帰属や利用条件を決定することになります。
(3)学習用プログラム
「学習用プログラム」とは、学習用データセットを利用して学習済みパラメータを生成するために用いられるプログラムのことをいいます。
学習用プログラムをスクラッチから生成することも可能ですが、今日では、OSS(Open Source Software)として公開されている機械学習ライブラリが広く利用されているため、学習用プログラムの権利帰属が問題となることは少ないといえます。
このようなOSSは、学習済みプログラムの作成の手間を軽減できるというメリットはありますが、開発目的に見合った学習済みモデルを生成するためには、OSSを利用するかどうかに関わらず、手法の選定について、高度な知識・経験・ノウハウといったものが必要になります。
ベンダが学習用プログラムを作成した場合において、その権利帰属・利用条件を定めるに際しては、学習済みモデルの生成後に、これとは別に新たな学習済みモデルを生成する必要性が生じうるという点に留意し、ユーザとベンダの利益をうまく調整することが重要です。
たとえば、ユーザにおいて、学習用データセットに新たなデータを加えて、学習済みモデルを生成する必要性が生じた場合には、学習用プログラムの利用についてベンダから許諾を受ける必要があります。
(4)学習済みモデル
学習済みモデルについては、以下の4点に注意する必要があります。
- 「学習済みモデル」の定義
- 提供の方法
- 権利帰属と利用条件
- 再利用モデルの扱い
①「学習済みモデル」の定義
「学習済みモデル」は、現時点ではっきりとした定義が存在しません。そのせいで、「学習済みモデル」の定義として、学習用データセットを含むのか、学習用プログラムまでも含むのか、学習済みパラメータと推論モデルを含むのかなどといった点を曖昧にしたまま、契約を締結するといったことが少なくありません。そうなると、後々、学習済みモデルの権利帰属などが問題となった場合に、その定義について紛争が生じる可能性があります。
このような紛争を避けるためにも、学習済みモデルの定義について、ユーザ・ベンダ間で共通認識を形成しておく必要があります。
②提供の方法
学習済みモデルは、学習用データセット・学習済みパラメータ・推論プログラムなどによって構成されていますが、これらを生成する過程では、多くのノウハウが活用されます。
場合によっては、ソースコードの提供などにおいて、判読可能な形式で学習済みモデルを提供すると、そこからノウハウが流出するおそれがあります。そのため、特別な事情がない限り、バイナリファイルを用いるなど、判読や二次利用が困難となるような形式で提供することが一般的です。
このように、学習済みモデルの提供方法は、そのことにより判読や二次利用が可能になっても問題ないか、といった観点から慎重に検討する必要があります。
③権利帰属と利用条件
学習済みモデルは、AIの本体とも言うべき成果物であるため、その権利帰属・利用条件は、交渉において重要な焦点になります。学習済みパラメータと推論プログラムから構成される学習済みモデルについて、どの部分にいかなる権利が成立するかについて、決まったルールがないこととも関連して、この点は特に問題となります。
この点は、後に見るように、学習済みパラメータには著作権法上の保護が及ばない可能性が高いこと、他方で、推論プログラムには著作権法や特許法上の保護が及ぶ可能性があることなどを念頭に置いて、利用条件などを定めることが必要になってきます。
④再利用モデルの扱い
「再利用モデル」とは、開発された学習済みモデルを再利用して、別の学習済みパラメータを搭載して作成された学習済みモデルのことをいいます。再利用モデルは、既に存在する学習済みモデルが基盤となっているため、同じモデルのようにも思えます。ですが、そこに搭載されているのは別の学習済みパラメータであることから、法的に同一のモデルであるといえるかどうかは現時点で明らかではありません。
そのため、ユーザ・ベンダの一方が他方に対し、学習済みモデルの利用目的や範囲を制限したい場合には、再利用モデルの生成を許すかどうかなどについても、契約上明確に定めておくべきだと考えられます。
もっとも、コンピュータ内部でソフトウェアがどのように用いられているかを外部から知ることは簡単ではありません。そのため、再利用モデルの生成を禁止することを契約で定めていたとしても、その違反を特定することは困難です。そのため、ユーザ・ベンダの利害対立が生じる可能性が高い取引時期や範囲などに制限を課すなど、契約の態様に何らかの制限を課すことを検討することが必要となるケースもありえます。
以上のように、学習済みモデルは成果物の中でも特に重要であるといえるため、まずは、ユーザ・ベンダ間で定義への共通認識をしっかりと形成しておくことが前提となります。そのうえで、権利帰属や利用条件など、問題となりうる点についての取り決めを細かく契約で明記しておくことが極めて重要です。
(5)学習済みパラメータ
「学習済みパラメータ」とは、学習用データセットを学習用プログラムに入力することで得られる数値(パラメータ)のことをいいます。学習済みパラメータは、単なる数値に過ぎないため、人が思想や感情を創作的に表現したものとは言いがたく、著作権法で保護される可能性は低いといえます。
そのため、いつでも学習済みパラメータにアクセスすることができるベンダはこれを自由に利用することが前提となります。そのうえで、学習済みパラメータの利用条件をユーザ・ベンダ間で協議し、契約で定めておくことが求められます。
もっとも、ユーザ・ベンダ間で学習済みモデルの利用方法に何ら制限のない契約が既に締結されており、かつ、判読可能な形で学習済みパラメータが提供されている場合には、ユーザの学習済みパラメータの利用についてベンダが認めていると考えられる可能性があります。
(6)推論プログラム
「推論プログラム」とは、学習済みモデルの主要な構成要素のうちの一つで、学習済みパラメータを組み込み、一定の結果を出力することができるプログラムのことをいいます。
このように、推論プログラムは、学習済みモデルから出力結果を得るために必要なプログラムです。そのため、ユーザ・ベンダ間で学習済みモデルの提供を内容とする契約が締結されている場合には、当然に推論プログラムをユーザが利用できるといった内容も契約に含まれているものと考えられます。
ここで注意しなければならないのは、学習済みモデルについての権利をユーザ・ベンダの両者に帰属させることを契約内容とする場合です。学習済みモデルを構成する推論プログラムは、その部分に創作性(オリジナリティ)が認められれば、「プログラム著作物」として著作権法による保護を受けられる可能性があります。また、プログラム部分が「自然法則を利用した技術的思想であり、創作性のあるもの」として「発明」にあたれば、特許で保護される可能性があります。
このように、推論プログラムには著作権法または特許法による保護が及ぶ可能性があるため、学習済みモデルの利用や譲渡、第三者提供の可否などについて、契約で明確にしておく必要があります。
(7)ノウハウ
「ノウハウ」とは、AI開発の過程において使われる、ベンダ・ユーザが独自に持つ知見や技術・情報を意味します。
この点、契約の実務では、学習用データセットや学習済みモデルの生成過程で使われるノウハウの取り扱いが問題となる場合があります。ベンダにとって、それまでに培ってきたノウハウは、競争力の源泉となるものが多いため、ノウハウの開示には慎重になることが通常です。
そのため、ベンダのノウハウについて開示することを内容とする契約を締結するにあたっては、ユーザ・ベンダ間の利益調整が必要になってきます。
他方で、ユーザがAI開発のために集めてきた生データには、ユーザのノウハウともいえる情報が含まれている場合があります。そのため、ユーザとしては、学習済みモデルの生成について一定の貢献度があることを主張してくる場合があります。このような場合には、ノウハウを用いたことによる一定の貢献度を加味したうえで、適切な利用条件などを設定するといった視点も必要になるものと考えられます。
以上のように、AI開発契約の交渉は成果物ごとにポイントが異なりますが、さらに、次の項目から見ていくように、利用態様に応じてケースもさまざまです。そのため、一つ一つの成果物について、ポイントとなる点を念頭に置きながら、ケースに見合った交渉をしていくことが大切です。
5 生データの継続利用のケース

まずは、ユーザから生データの提供を受けたベンダが、学習済みモデルの提供後も生データを継続して利用したいと考えているケースについて見ていきましょう。

生データを継続利用するケースでは、以下のように、5つの工程でAI開発が実施されます。
- ユーザが、生データをベンダに提供する
- ベンダが、学習用プログラム・学習用データセットを生成する
- ベンダが、学習済みモデルを生成する
- ベンダが、学習済みモデルをユーザに納品する
- ベンダが、ユーザのデータを別の学習済みモデル生成に利用する
このケースでは、ユーザが生データをベンダに提供し、ベンダが学習用データセットに成型し、あらかじめ用意しておいた学習用プログラムに入力することで生成された学習済みモデルをユーザに納品することになります。この場合において、ベンダはユーザに学習済みモデルを納品した後も引き続きユーザから提供を受けた生データを利用し、ユーザの競業会社から提供を受けたデータとあわせて、精度の良い学習済みモデルの生成のために利用したいと考えていたとします。
この場合、前提として、ベンダはユーザから生データを提供される際に、秘密保持契約(NDA)をユーザとの間で結ぶのが一般的です。そのため、ベンダは生データを第三者に開示したり、ユーザのために学習済みモデルを生成する以外の目的で使うことはできません。
ベンダがユーザから提供を受けた生データを継続して利用するためには、学習済みモデルの品質・性能の向上のためだけにそのデータを利用できるといった条件をつけ、そのことについて、ユーザやユーザの競業会社から許諾を得ることが考えられます。この場合には、更新した学習済みモデルを継続的に提供するという利用条件も併せて設定することが考えられます。
6 追加学習のケース

次に見ていくのは、ベンダから学習済みモデルの提供を受けた別のベンダが、学習済みモデルに加え学習用プログラムの提供を受けて、これに追加学習を行うサービスを提供したいと考えているケースです。
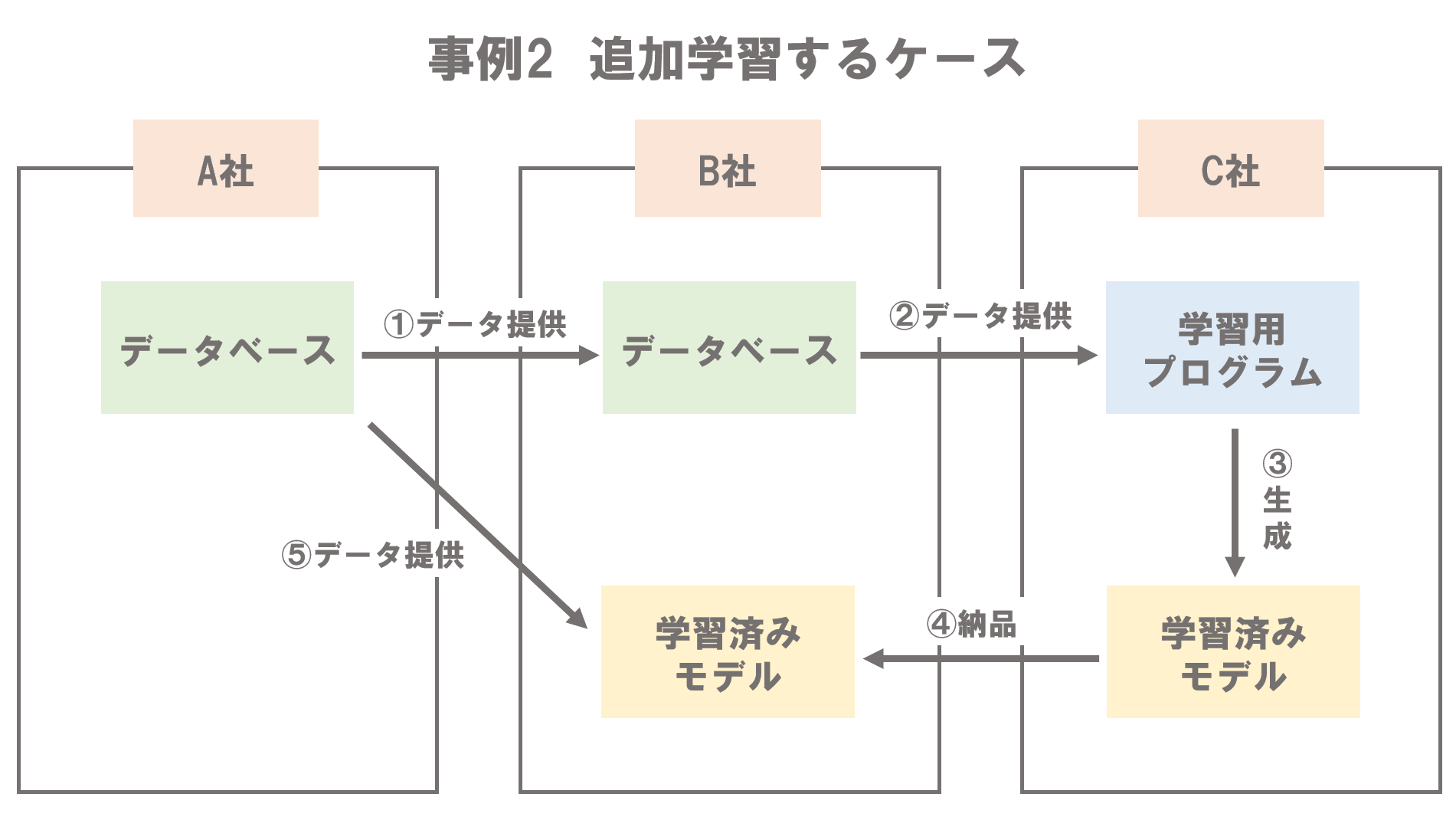
追加学習するケースでは、以下のように、6つの工程でAI開発が実施されます。
- A社が、B社にデータを提供する
- B社は、A社から提供を受けたデータをC社に提供する
- C社は、それを基に生成した学習用データセットを学習用プログラムに入力し学習済みモデルを生成する
- C社は、学習済みモデルをB社に納品する
- A社が、あらたなデータをB社に提供し、B社が学習用データセットを生成する
- B社が、C社から提供を受けた学習用プログラムを用いて、C社から提供を受けた学習済みモデルに追加学習させる
このケースでは、C社から学習用プログラムの提供を受けたB社は、学習プログラムから、C社の重要なノウハウを読み取ることができる可能性があります。
このような場合において、C社のノウハウが、研究や開発の積み重ねによって培われたものである場合や独創性(オリジナリティ)が認められるようなものである場合には、C社にとって、ノウハウは貴重な価値があるものとなります。
そのため、C社が何ら対価を得ることなく学習用プログラムの利用を許可する可能性は低いといえます。
他方で、B社による追加学習のサービスは事業における競争力を生み、また、C社のノウハウにそこまでの価値は認められないとB社が考えている場合には、両者間で主張が衝突しているため、B社とC社との間に契約が成立することは難しいといえます。
このような場合には、B社による追加学習のサービスを可能とする範囲でC社が利用を許諾するものとし、その対価について調整することが可能である場合にだけ、契約が締結されるものと考えられます。
7 段階別学習済みモデルの提供のケース

次は、学習済みモデルの提供を内容とする契約を締結したユーザ・ベンダが、現場で実際にこれを使って評価をしたい、また、学習済みモデルにはユーザの現場情報が含まれることから、ベンダが再利用することを防止したいとユーザが考えているケースについて見てみましょう。

段階別学習済みモデル提供のケースでは、以下のように、4つの工程でAI開発が実施されます。
- ユーザが、理想的な環境で得られた生データをベンダに提供する
- ベンダが、ユーザから提供を受けた生データを基に生成した学習用データセットを学習用プログラムに入力することにより学習済みモデルを生成する
- ベンダが、学習済みモデルをユーザに納品する
このケースでは、ユーザが理想的な環境下で生データを収集し、その生データの提供を受けたベンダが学習済みモデルを生成することになります。
もっとも、生成された学習済みモデルは理想的な環境下で収集されたデータを用いているため、その精度がそのまま現場環境下でも維持されるとは限りません。そのため、生成された学習済みモデルが、ユーザの現場環境下で期待した精度を維持できるかどうかをテストして性能を評価することが必要になってきます。
このようなテストを実施する一つの方法として、開発途中の学習済みモデルをユーザに提供することが考えられますが、そこにはベンダの価値あるノウハウなどが含まれています。
そのため、このような場合には、ユーザとの間で秘密保持契約を締結したうえで、学習済みモデルをユーザに提供し、学習済みモデルの性能を評価することに限定して利用することを条件として付けることが考えられます。
また、ユーザにとって知られたくない現場情報などが学習済みモデルに反映されているような場合には、その情報が競業他社などに流出することを防ぐために、学習済みモデルに関する権利をユーザに帰属させて、ベンダによる(再)利用を認めないこととしたり、目的を限定してベンダに利用を許可したり、ユーザの競業他社には提供しないといった条項を契約に盛り込むことが考えられます。
8 多数の当事者による学習済みモデルの生成のケース

最後に見るのは、複数のユーザとベンダとの間で学習済みモデルの提供を内容とした契約が締結された場合において、契約の当事者となっている者すべてが学習済みモデルを自由に使いたいと考えているケースです。

多数当事者による学習済みモデル生成のケースでは、以下のように、3つの工程でAI開発が実施されます。
- B社とC社からデータの提供を受けたA社が、学習用データセットを生成する
- A社は、生成した学習用データセットを学習用プログラムに入力することにより、学習済みモデルを生成する
- A社は、B社とC社に学習済みモデルをそれぞれ納品する
このケースでは、同じ業界のB社とC社それぞれから生データの提供を受けたA社が、これを基に生成した学習用データセットを用いて学習済みモデルを生成し、B社とC社に納品することになります。
このように、当事者が複数いるケースでは、その数が増えるほど契約上の利害が対立しやすくなります。
たとえば、お菓子を製造する2社から提供されたデータを基に、新商品を提案する学習済みモデルが生成された場合、ベンダに学習済みモデルの利用を認めるか、また、それぞれにどのような条件で学習済みモデルを利用させるか、という点について、三者間で協議する必要があります。この場合、各社が投じたコストや労力を考慮して、利益の調整を図ることになるものと考えられます。
たとえば、スナック菓子を主に製造しているB社はスナック菓子の分野でのみ学習済みモデルを利用できることとし、チョコレート菓子を主に製造しているC社はチョコレート菓子の分野でのみ学習済みモデルを利用できることとするというような調整が可能だと考えられます。
9 小括

AI開発契約の交渉にあたっては、その前提として、AI開発過程では様々な成果物が生み出されるということをきちんと理解したうえで、それぞれの成果物に存在する問題点や特徴をチェックしておくことが重要です。
そのうえで、それぞれの成果物にある独自の留意点を念頭に、定義や権利帰属・利用条件などといった基本的な事項を明確にしたうえで交渉を進めていくことが大切です。
10 まとめ
これまでの解説をまとめると、以下のようになります。
- AI開発契約とは、AIを開発する際に、ユーザとベンダの間で締結される契約のことである
- AI開発と通常のシステム開発は開発の思想が大きく異なる
- AI開発について、経産省ガイドラインでは、①アセスメント段階、②PoC段階、③開発段階、④追加学習段階の4つに分ける「探索的段階型」の開発方式が提唱されている
- AI開発契約は、その性質を①請負契約、②履行割合型の準委任契約、③成果完成型の準委任契約に分けることができる
- AI開発では、その過程で①生データ、②学習用データセット、③学習用プログラム、④学習済みモデル、⑤学習済みパラメータ、⑥推論プログラム、⑦ノウハウといった成果物が生み出される
- AI開発契約にあたっては、AI開発の成果物それぞれについて、開発への貢献度を踏まえるなどして、権利帰属と利用条件について交渉していく必要がある
- 学習済みモデルの性能評価をする場合は、秘密保持契約を締結したうえで、一定の条件をみたした環境に限定して実施することが考えられる
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
IT・EC・金融(暗号資産・資金決済・投資業)分野を中心に、スタートアップから中小企業、上場企業までの「社長の懐刀」として、契約・規約整備、事業スキーム設計、当局対応まで一気通貫でサポートしています。 法律とビジネス、データサイエンスの視点を掛け合わせ、現場の意思決定を実務的に支えることを重視しています。 【経歴】 2006年 弁護士登録。複数の法律事務所で、訴訟・紛争案件を中心に企業法務を担当。 2015年~2016年 知的財産権法を専門とする米国ジョージ・ワシントン大学ロースクールに留学し、Intellectual Property Law LL.M. を取得。コンピューター・ソフトウェア産業における知的財産保護・契約法を研究。 2016年~2017年 証券会社の社内弁護士として、当時法制化が始まった仮想通貨交換業(現・暗号資産交換業)の法令遵守等責任者として登録申請業務に従事。 その後、独立し、海外大手企業を含む複数の暗号資産交換業者、金融商品取引業(投資顧問業)、資金決済関連事業者の顧問業務を担当。 2020年8月 トップコート国際法律事務所に参画し、スタートアップから上場企業まで幅広い事業の法律顧問として、IT・EC・フィンテック分野の契約・スキーム設計を手掛ける。 2023年5月 コネクテッドコマース株式会社 取締役CLO就任。EC・小売の現場とマーケティングに関わりながら、生成AIの活用も含めたコンサルティング業務に取り組む。 2025年2月 中小企業診断士試験合格。同年5月、中小企業診断士登録。 2025年9月 一橋大学大学院ソーシャル・データサイエンス研究科(博士前期課程)合格。







