












AI開発契約の品質保証とは?3つのチェックポイントを弁護士が解説

はじめに
AI開発は「やってみないとわからない」という特性をもつため、AI開発契約において、「品質保証」や「事後の検収」などをどのように契約書に定めたらいいのか、よくわからないという事業者が多いと思います。
この点、多くのケースにおいて、ユーザ・ベンダにおけるAI技術への理解のズレが原因となって、双方の言い分に食い違いが生じます。たとえば、AI開発により生成される学習済みモデルについて、ユーザはベンダに対して性能保証を求めるのに対し、ベンダは性能保証をしたがらない、といったようなことが生ずるわけです。
そこで今回は、AI開発における「品質保証」や「事後の検収」などをどのように考えるべきか、その対応策や、AI開発契約における法的な注意点をITに詳しい弁護士が解説します。
1 AI開発契約とは

「AI開発契約」とは、主にユーザがベンダに対し、AI技術を用いたソフトウェアの開発を委託することを内容とする契約です。そのフローは、以下の図のようになります。
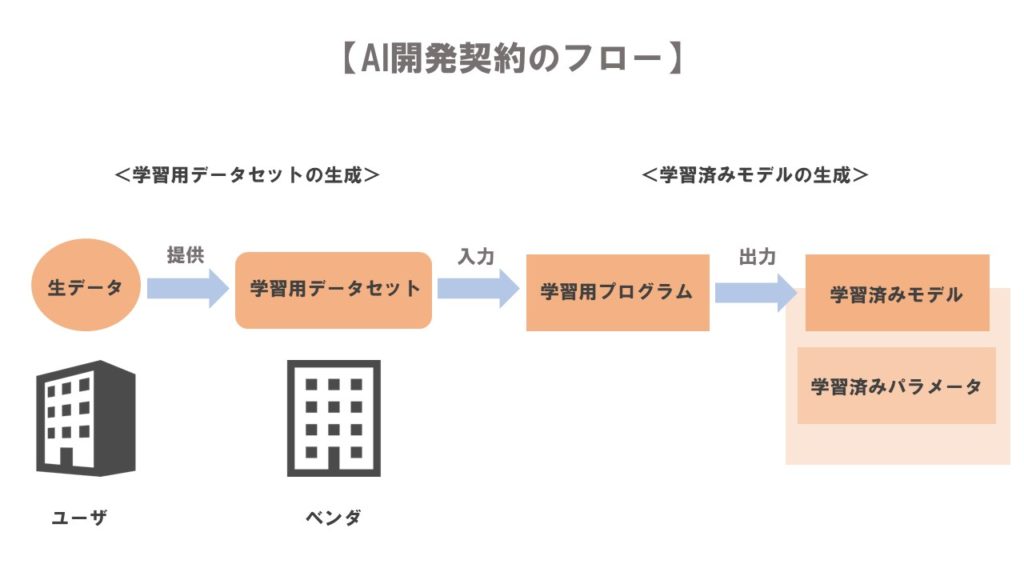
このように、AI開発契約は、
- ユーザが、「生データ」を提供する
- ベンダが、AIプログラムを開発する
- ベンダが、学習用データセットを生成する
- ベンダが、学習済みパラメータを作成する
- ベンダが、学習済みモデルを完成させる
という流れで進んで行くことになります。
このフローからも分かるように、AI技術を用いたソフトウェアの開発は、その生成方法において、従来のソフトウェア開発とは異なります。後に詳しく解説しますが、AI開発契約を結ぶにあたっては、この点を十分に理解しているかどうかが大変重要なポイントになってきます。
2 AI開発契約と通常のソフトウェア開発契約の違い

AI開発と通常のソフトウェア開発の違いについては、以下の図を使って見ていきたいと思います。
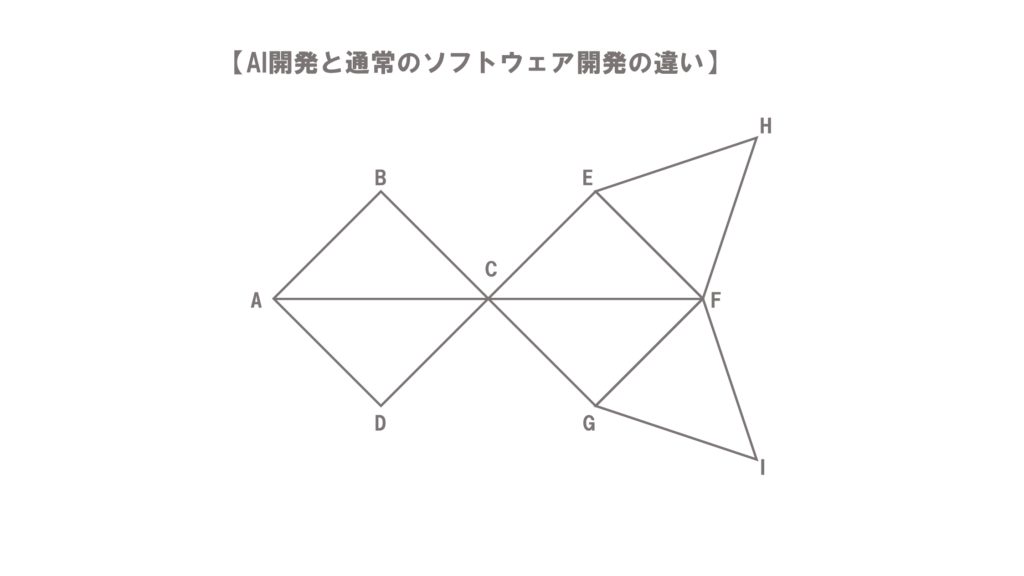
AI開発と通常のソフトウェア開発には、開発のプロセスや手法において、以下のような違いがあります。
-
【AI開発】
AからCに行く道であったり、CからH・F・Iに行く道であったり、多くの組み合わせの経路をデータとして取り込み、また、実際にAからFまで人々がどのような順序で行くかなどのデータを加えます。
このように、AI開発は、開発に必要となる大量のデータを集めてきて、それを使って学習させ、それらのデータに共通する法則などを見出そうとする手法です。
もっとも、取り込んだデータの中には、道に迷ってしまってHやIにたどり着いたり、迷ってしまった結果Fに行くのをあきらめてしまったといったサンプル(外れ値)が含まれている可能性があります。
-
【通常のソフトウェア開発】
AからFにたどり着くにはCに行く必要があります。そのため、まずはAからCに行き、そして、CからFに向かうといったように、Fという目標に向かって直線的に進むイメージで行われます。
このように、通常のソフトウェア開発は、目標から逆算して、目標を達成するために必要なことを積み上げていく手法です。
このように、AI開発と通常のソフトウェア開発とでは「手法」が異なるため、AI開発契約においても、注意すべき法的なポイントが通常のソフトウェア開発契約とは違ってきます。具体的には、AI開発契約と通常のソフトウェア開発契約との間には、主に以下の3点に違いがあります。
- 性能保証
- 事後的な検収の困難性
- 瑕疵担保
(1)性能保証
「性能保証」とは、通常のソフトウェア開発でよく行われるもので、成果物の性能についてベンダが一定の保証をすることを意味します。
もっとも、AI開発は「やってみないとどうなるか分からない」という特徴があるため、ベンダの心境としては、通常のソフトウェア開発で行われるような性能保証をそのままAI開発においても行うことは困難です。
この点を理解していないと、AI開発の局面では、
- ユーザ:一定の性能保証をベンダにしてもらいたい
- ベンダ:やってみないとどうなるか分からない以上、性能保証はできない
といったように、ユーザ・ベンダ間に「性能保証」への考え方について食い違いが生じます。
(2)事後的な検収の困難性
「事後的な検収」とは、納品された製品の性能が注文内容を満たしているかを確認する作業のことを言います。通常のソフトウェア開発では、納品されたシステムをユーザがテストするなどの方法により検収を行います。
他方で、AI開発においては、完成したモデルを用いて検収を行うことになりますが、仮に検収の結果、問題が発見されたとしても、その問題がデータ・AIプログラム・ソースコードのいずれにあるのかを特定することが困難であるというネックがあります。
そのため、AI開発契約においては、通常のソフトウェア開発契約と異なり、事後的な検収が困難であるということが言えます。
(3)瑕疵担保責任
「瑕疵担保責任」とは、納品された製品に、一見分からないような欠陥(=瑕疵)があった場合に、その責任を負担することをいいます。製品に瑕疵があることが発覚した場合、注文者は「契約の解除」や「損害賠償請求」が可能になります。
通常のソフトウェア開発では、始めに確定された仕様の実現に必要とされることを積み上げていくことになるため、何をもって「瑕疵」といえるかは比較的ハッキリします。
他方で、AI開発では、一定のデータを入力した場合に、どのような結果を得られるかということが予測困難であるため、何をもって「瑕疵」といえるかもハッキリとしません。
そのため、瑕疵担保責任に対する考え方も、「性能保証」と同じように、ユーザとベンダとの間に食い違いが生じるのです。
以上のように、AI開発契約と通常のソフトウェア開発契約との間には、開発上の違いなどから大きな違いがあります。ユーザ・ベンダにおいて、その点を十分に理解していないと、さまざまな食い違いが生じやすくなり、場合によっては、AI開発契約を締結することが難しくなってしまいます。
そのため、AI開発契約を締結する際には、AI開発契約と通常のソフトウェア開発契約の違いを十分に理解しておくことが極めて重要になるうえ、次の項目で見るチェックポイントをしっかりと押さえておくことが必要になってきます。
3 AI開発契約を締結する際のチェックポイント

AI開発契約を締結する際のチェックポイントとしては、
- 共通認識の形成
- 4つの段階に分けた開発方式
- 柔軟性のある契約内容
という3点が挙げられます。
4 ポイント①:共通認識の形成

ユーザとベンダがAI開発契約を結ぶ際に、多くのケースで見受けられるのが、AI技術についての理解のズレです。
先に見たように、AI開発は、開発に必要となる大量のデータを集めてきて、それを使って学習させ、それらのデータに共通する法則などを見出そうとする手法であり、大量のデータの中には、外れ値といった開発目的とは関係のないデータも含まれています。
また、学習済みモデルの精度に影響を与える「統計的バイアス(偏り)」を取り除く作業が実施されるものの、すべてを取り除けるとは限りません。
このように、AI開発は、通常のソフトウェア開発とは異なり、「やってみないとどうなるか分からない」という要素が強い手法であるため、どのような精度のAIが完成するかをあらかじめ予想することも困難です。
そのため、ベンダにおいて、AIに関し一定の性能をあらかじめ保証するようなことはできません。ユーザがベンダに対し、AIについて一定の性能保証を求めたがるケースでは、ユーザがこのようなAI開発の特性を理解していないことが原因として考えられます。
AI開発契約を締結する際には、このようなAI開発の特性をユーザ・ベンダがお互いに理解して共通認識を形成することが非常に重要なポイントとなります。
5 ポイント②:4つの段階に分けた開発方式

繰り返しになりますが、AI開発には、「やってみないと分からない」という特徴があります。そのため、あらかじめ契約の内容をすべてカッチリと決めることは困難ですし、またどのようなリスクが生じるかをあらかじめ想定し、リスク負担をすべて明確にしておくということも難しいといえます。
とはいえ、あまりに大雑把に契約内容を定めてしまうと、予期せぬ問題に直面した場合に、リスク負担などについて、トラブルのもとになってしまいます。
この問題も、AI開発の特性に起因するものですが、対応策として経産省のAIガイドラインでは「探索的段階型」という開発方式が提唱されています。
具体的には、契約を開発の過程に応じて、いくつかのフェーズに分割して、ユーザ・ベンダ間で問題がないかどうかをフェーズごとに確認し、前に進めていく方法です。
このような方法を採ることにより、開発上問題が生じた時の対応を適宜きめ細やかに行えるようになります。また、フェーズごとに、それまでの開発に問題がないか、このまま開発を進めて問題ないか、などといった点をユーザ・ベンダ間で確認することが可能になるため、仮に、開発を中止するような場合にもその判断を適切な時期に行うことができ、損失の拡大を防ぐことが可能になります。
以下は、「探索的段階型」の開発方式を図にしたものです。
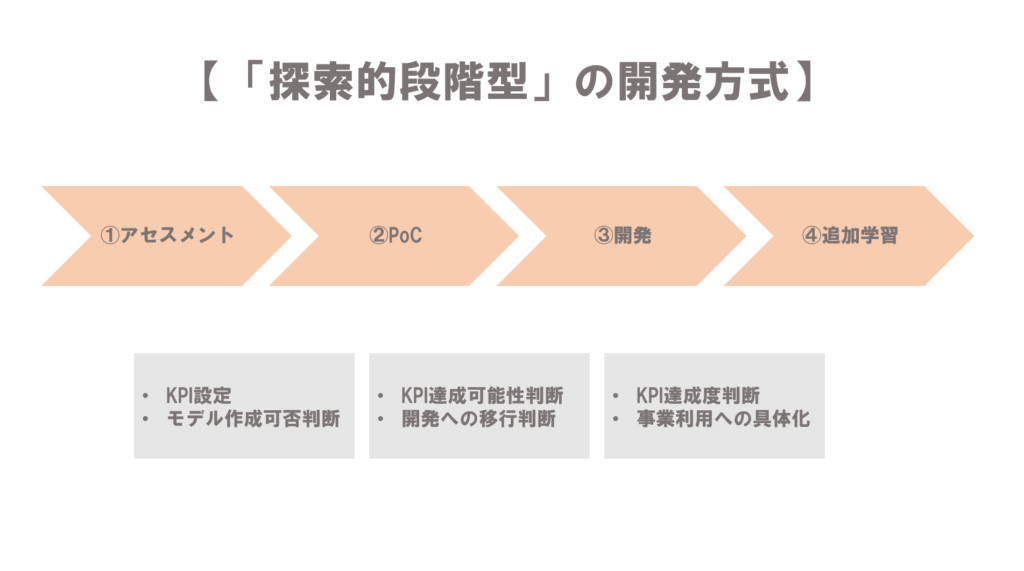
このように、「探索的段階型」という開発方式は、AI開発を、
- アセスメント段階
- PoC段階
- 開発段階
- 追加学習段階
という4つの段階に分けて捉える方法です。
(1)アセスメント段階
「アセスメント段階」とは、ユーザ・ベンダ間で秘密保持契約(NDA)を締結したうえで、ユーザから提供された一定のデータをもとに、ユーザが求める学習済みモデルを生成できるかどうかを事前検証する(=モデル作成可否判断)段階のことをいいます。
アセスメント段階は、ユーザ・ベンダ間でAI開発への共通認識を形成する段階でもあります。そのため、AIを導入することでユーザは何を達成したいのかということを可能な限り具体化することが重要になってきます。また、どのような場合にその課題を達成したものと評価するか(=KPI設定)という点も重要になってきます。
このように、アセスメント段階では、AI開発で生成された学習済みモデルをユーザはどのように事業に活かしたいのか、ということを具体化することで、そのためにはどのようなデータが必要となるのか、必要なデータはきちんと確保できるのかなどといった点をユーザ・ベンダ間で検証することが可能になるのです。
(2)PoC段階
「PoC」とは「概念実装(Proof of Concept)」の略で、ユーザやベンダが保持する生データに基づき、学習済みモデルを生成することが可能かどうかを実際に検証する段階のことをいいます。具体的には、生データの一部を用いて、試作的に学習済みモデルを生成するなどして、ユーザが求めるAI開発が可能かどうかを検証することになります。ここでは、あわせてアセスメント段階で設定したKPIを達成できそうかどうかという点も検証することになります(=KPI達成可能性判断)。
また、PoC段階では、学習済みモデルのパイロットテストを行うこともあります。
「パイロットテスト」とは、本番の開発に移る前に実施される試験的な運用を意味します。具体的には、あらかじめ用意しておいたシステムの一部に学習済みモデルを実装し、システムになじませた後に、性能を評価するという形で行われます。たとえば、ノートパソコンに外付けキーボードを接続して機能するかどうかを確認するようなイメージです。
PoCを実施することにより、学習済みモデルが生成されることもあり、その場合は、生成された学習済みモデルの権利帰属や利用条件をユーザ・ベンダ間で話し合う必要があります。
(3)開発段階
「開発段階」では、実際に学習用データセットを用いて学習済みモデルを生成することになります。
(4)追加学習段階
「追加学習段階」では、ベンダが生成・納品した学習済みモデルに、追加の学習用データセットを読み込ませることで再び学習をさせる段階です。学習済みモデルを生成したベンダが追加学習を支援することもありますが、別のベンダが行うこともあります。
このように、AI開発を開発過程に応じていくつかのフェーズに分けることで、ユーザ・ベンダ間でその都度状況を確認しながら、共通認識をもって開発を進めることが可能になります。そうすることで、双方に存在する考え方の食い違いを早期に確認・解消することも可能になるのです。
※「探索的段階型」の開発方式について、詳しく知りたい方は、経済産業省が出している「AI・データの利用に関する契約ガイドライン ーAI編ー 」(P43)をご覧ください。
6 ポイント③:柔軟性のある契約内容

通常のソフトウェア開発契約とAIの開発契約との間には、既に見てきたように、開発上の違いがあります。そのため、学習済みモデルについてベンダが一定の「性能保証」をするということは基本的には困難だと考えられています。
とはいえ、ユーザからすれば、AIを開発するために高いお金を支払っているのに、性能保証をまったく受けられないのでは到底納得できるものではありません。
このような問題への対応策として、経産省ガイドラインでは、以下の2つの方法が示されています。
- 既知の評価用データを入力した場合の性能保証
- 準委任契約における成果完成型を用いる
(1)既知の評価用データを入力した場合の性能保証
既知の評価用データを入力した場合の学習済みモデルの性能については、評価条件を適切に設定・限定することができれば、その学習済みモデルについて一定の性能保証をすることが合理的な場合もあります。
このような場合には、ユーザ・ベンダ間で締結する契約は、学習済みモデルを仕事の完成物とし、きちんとした物を完成する義務を負担する「請負契約」(⇔(準)委任契約)として検討することになると考えられます。
既知の評価用データであれば、学習済みモデルの推論精度に影響を及ぼさないため、そのかぎりで性能保証をすることが可能です。
ここで注意しなければならないのは、入力される評価用データにおいて、ユーザの事業におけるリスクがきちんと評価されているかという点です。
この点は、ユーザが把握していることが通常であるため、評価用データは原則としてユーザが費用と責任を負担して準備することが多いと考えられます。
このように、既知の評価用データを入力した場合の性能保証については、可能な場合もありますが、ユーザが以上のような費用と責任を負担してまで性能保証を求めることが必要かどうかを慎重に検討することが重要になってきます。
(2)準委任契約における成果完成型を用いる
「準委任契約」とは、権利の発生・消滅を伴わない事務を依頼する契約です。準委任契約は、売買契約や請負契約とは異なり、成果物を生み出すための最善の努力をすれば足り、成果物をきちんと完成させる義務はありません。
そのため、ベンダ側に完成義務があることを前提とし、想定される品質に至っていない場合の責任追求の手段である「瑕疵担保責任」を負うことはありません。
準委任契約には、以下の2つの種類があります。
- 履行割合型
- 成果完成型
①履行割合型
「履行割合型の準委任契約」とは、「事務処理の労務に対して報酬が支払われる」契約のことをいい、提供した労働時間や作業の工数に応じて報酬が支払われることになります。そのため、ユーザはベンダによる開発が成功しなくとも、ベンダがAIの開発に割いた時間や作業の工数に応じた報酬を支払わなければなりません。
このように、AI開発契約について「履行割合型」を採用すると、結果として、ユーザは性能保証を受けられないことになります。
②成果完成型
「成果完成型の準委任契約」とは、「事務処理の結果として達成された成果に対して報酬が支払われる」契約のことをいいます。成果完成型では、たとえ、ベンダにおいて多くの労働時間や作業の工数を割いていても、成果がまったくなければ報酬は支払われないことになります。
そのため、ベンダが学習済みモデルを生成できなかった場合には、報酬も発生しません。
なお、成果完成型の準委任契約は、あくまでも委任契約であって請負契約ではないので、仕事の完成義務までは負わないことには注意が必要です。
このように見てくると、成果完成型では、最悪の場合、ベンダが開発を放棄したり、報酬を一方的に放棄するといった場面が想定されます。
この点、準委任契約では、ベンダに「善管注意義務」という義務が課せられます。
「善管注意義務」とは、業務を委任された者がその職業や専門的な立場から通常求められる注意義務のことをいいます。このような義務がベンダに課される以上、開発を勝手にやめてしまうと、場合によっては、損害賠償責任を負わなければならなくなります。
「成果完成型」は、ベンダにとっては、請負契約のように完成義務などを負うことなく結べる契約形態であるため、利点のある契約形態といえます。
また、ユーザにとっても、ベンダが一定の成果を生まないかぎり、報酬を支払わなくていいという点で、一定の「性能保証」を受けられていると考えることも可能です。
以上のように、既知の評価用データを用いる方法や、成果完成型の準委任契約を採用することで、性能保証を行うことが可能になるものと考えられます。
7 小括

AI開発と通常のソフトウェア開発は、開発上の性質が全く異なります。
そのため、AI開発契約を締結するにあたっては、ユーザ・ベンダ間において、この点について共通の理解をもっておくことが重要です。
ユーザ・ベンダ間でAI開発への理解を共有することで、AI開発に向けて工夫のある契約を締結することができるようになります。ユーザ・ベンダ間で無用な争いが起きないようにするためにも、経済産業省のガイドラインなどを参考にしつつ、ユーザ・ベンダ間で協議を重ねることが大切です。
8 まとめ
これまでの解説をまとめると、以下のようになります。
- AI開発契約と通常のソフトウェア開発との間には、①性能保証、②事後的な検収の困難性、③瑕疵担保という3つの点に違いがある
- AI開発契約を締結する際のチェックポイントは、①共通認識の形成、②4つの段階に分けた開発方式、③柔軟性のある契約内容、の3点である
- AI開発について、経産省ガイドラインでは「探索的段階型」という開発方式が提唱されている
- AI開発における「性能保証」について、経産省ガイドラインでは、①既知の評価用データを入力した場合の性能保証、②準委任契約における成果完成型を用いる、という2つの方法が示されている
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
現在は、企業法務を中心とした弁護士業務と、一橋大学大学院ソーシャル・データサイエンス研究科(M1)における研究の2軸で活動しています。 弁護士としては、IT・ゲーム・AI・FinTech分野を中心に、契約・利用規約、知的財産、個人情報保護、資金決済・金融規制、企業法務などを取り扱っています。 大学院では、法令工学を基盤として、法令データの構造化や生成AI・データサイエンスを活用した法情報処理に関する研究に取り組んでいます。







